I first wrote about the Metaverse in 2018, and overhauled my thinking in a January 2020 update: The Metaverse: What It Is, Where to Find it, Who Will Build It, and Fortnite. Since then, a lot has happened. COVID-19 forced hundreds of millions into Zoomschool and remote work. Roblox became one of the most popular entertainment experiences in history. Google Trends’ index on the phrase ‘The Metaverse’ set a new ‘100’ in March 2021. Against this baseline, use of the term never exceeded seven from January 2005 through to December 2020. With that in mind, I thought it was time to do an update - one that reflects how my thinking has changed over the past 18 months and addresses the questions I’ve received during this time, such as “Is the Metaverse here?”, “When will it arrive?”, and “What does it need to grow?”. Welcome to the Foreword to ‘THE METAVERSE PRIMER’.
When did the mobile internet era begin? Some would start this history with the very first mobile phones. Others might wait until the commercial deployment of 2G, which was the first digital wireless network. Or the introduction of the Wireless Application Protocol standard, which gave us WAP browsers and thus the ability to access a (rather primitive) version of most websites from nearly any ‘dumbphone’. Or maybe it started with the BlackBerry 6000, or 7000 or 8000 series? At least one of them was the first mainstream mobile device designed for on-the-go data. Most would say it’s the iPhone, which came more than a decade after the first BlackBerry and eight years after WAP, nearly two decades after 2G, 34 years after the first mobile phone call, and has since defined many of the mobile internet era’s visual design principles, economics, and business practices.
In truth, there’s never a flip. We can identify when a specific technology was created, tested, or deployed, but not when an era precisely occurred. This is because technological change requires a lot of technological changes, plural, to all come together. The electricity revolution, for example, was not a single period of steady growth. Instead, it was two separate waves of technological, industrial, and process-related transformations.
The first wave began around 1881, when Thomas Edison stood up electric power stations in Manhattan and London. Although this was a quick start to the era of electrical power — Edison had created the first working incandescent light bulb only two years earlier, and was only one year into its commercialization — industrial adoption was slow. Some 30 years after Edison’s first stations, less than 10% of mechanical drive power in the United States came from electricity (two thirds of which was generated locally, rather than from a grid). But then suddenly, the second wave began. Between 1910 and 1920, electricity’s share of mechanical drive power quintupled to over 50% (nearly two thirds of which came from independent electric utilities. By 1929 it stood at 78%).
The difference between the first and second waves is not how much of American industry used electricity, but the extent to which it did — and designed around it.
When plants first adopted electrical power, it was typically used for lighting and/or to replace a plant’s on-premises source of power (usually steam). These plants did not, however, rethink or replace the legacy infrastructure which would carry this power throughout the factory and put it to work. Instead, they continued to use a lumbering network of cogs and gears that were messy and loud and dangerous, difficult to upgrade or change, were either ‘all on’ or ‘all off’ (and therefore required the same amount of power to support a single operating station or the entire plant, and suffered from countless ‘single points of failure’), and struggled to support specialized work.
But eventually, new technologies and understandings gave factories both the reason and ability to be redesigned end-to-end for electricity, from replacing cogs with electric wires, to installing individual stations with bespoke and dedicated electrically-powered motors for functions such as sewing, cutting, pressing, and welding.
The benefits were wide-ranging. The same plant now had considerably more space, more light, better air, and less life-threatening equipment. What’s more, individual stations could be powered individually (which increased safety, while reducing costs and downtime), and use more specialized equipment (e.g. electric socket wrenches).
In addition, factories could configure their production areas around the logic of the production process, rather than hulking equipment, and even reconfigure these areas on a regular basis. These two changes meant that far more industries could deploy assembly lines in their plants (which had actually first emerged in the late 1700s), while those that already had such lines could extend them further and more efficiently. In 1913, for example, Henry Ford created the first moving assembly line, which used electricity and conveyor belts to reduce the production time per car from 12.5 hours to 93 minutes, while also using less power. According to historian David Nye, Ford’s famous Highland Park plant was “built on the assumption that electrical light and power should be available everywhere.”
Once a few plants began this transformation, the entire market was forced to catch up, thereby spurring more investment and innovation in electricity-based infrastructure, equipment, and processes. Within a year of its first moving assembly line, Ford was producing more cars than the rest of the industry combined. By its 10 millionth car, it had built more than half of all cars on the road.
This ‘second wave’ of industrial electricity adoption didn’t depend on a single visionary making an evolutionary leap from Thomas Edison’s core work. Nor was it driven just by an increasing number of industrial power stations. Instead, it reflected a critical mass of interconnected innovations, spanning power management, manufacturing hardware, production theory, and more. Some of these innovations fit in the palm of a plant manager’s hand, others needed a room, a few required a city, and they all depended on people and processes.
To return to Nye, “Henry Ford didn’t first conceive of the assembly line and then delegate its development to his managers. … [The] Highland Park facility brought together managers and engineers who collectively knew most of the manufacturing processes used in the United States … they pooled their ideas and drew on their varied work experiences to create a new method of production.” This process, which happened at national scale, led to the ‘roaring twenties’, which saw the greatest average annual increases in labor and capital productivity in a hundred years.
Powering the Mobile Internet
This is how to think about the mobile internet era. The iPhone feels like the start of the mobile internet because it united and/or distilled all of the things we now think of as ‘the mobile internet’ into a single minimum viable product that we could touch and hold and love. But the mobile internet was created — and driven — by so much more.
In fact, we probably don’t even mean the first iPhone but the second, the iPhone 3G (which saw the largest model-over-model growth of any iPhone, with over 4× the sales). This second iPhone was the first to include 3G, which made the mobile web usable, and operated the iOS App Store, which made wireless networks and smartphones useful.
But neither 3G nor the App Store were Apple-only innovations or creations. The iPhone accessed 3G networks via chips made by Infineon that connected via standards set by the ITU and GSMA, and which were deployed by wireless providers such as AT&T on top of wireless towers built by tower companies such as Crown Castle and American Tower. The iPhone had “an app for that” because millions of developers built them, just as thousands of different companies built specialized electric motor devices for factories in the 1920s. In addition, these apps were built on a wide variety of standards — from KDE to Java, HTML and Unity — which were established and/or maintained by outside parties (some of whom competed with Apple in key areas). The App Store’s payments worked because of digital payments systems and rails established by the major banks. The iPhone also depended on countless other technologies, from a Samsung CPU (licensed in turn from ARM), to an accelerometer from STMicroelectronics, Gorilla Glass from Corning, and other components from companies like Broadcom, Wolfson, and National Semiconductor.
All of the above creations and contributions, collectively, enabled the iPhone and started the mobile internet era. They also defined its improvement path.
Consider the iPhone 12, which was released in 2020. There was no amount of money Apple could have spent to release the iPhone 12 as its second model in 2008. Even if Apple could have devised a 5G network chip back then, there would have been no 5G networks for it to use, nor 5G wireless standards through which to communicate to these networks, and no apps that took advantage of its low latency or bandwidth. And even if Apple had made its own ARM-like GPU back in 2008 (more than a decade before ARM itself), game developers (which generate more than two thirds of App Store revenues) would have lacked the game-engine technologies required to take advantage of its superpowered capabilities.
Getting to the iPhone 12 required ecosystem-wide innovation and investments, most of which sat outside Apple’s purview (even though Apple’s lucrative iOS platform was the core driver of these advancements). The business case for Verizon’s 4G networks and American Tower Corporation’s wireless tower buildouts depended on the consumer and business demand for faster and better wireless for apps such as Spotify, Netflix and Snapchat. Without them, 4G’s ‘killer app’ would have been… slightly faster email. Better GPUs, meanwhile, were utilized by better games, and better cameras were made relevant by photo-sharing services such as Instagram. And this better hardware powered greater engagement, which drove greater growth and profits for these companies, thereby driving better products, apps, and services. Accordingly, we should think of the overall market as driving itself, just as the adoption of electrical grids led to innovation in small electric-powered industrial motors that in turn drove demand for the grid itself.
We must also consider the role of changing user capability. The first iPhone could have skipped the home button altogether, rather than waiting until the tenth. This would have opened up more room inside the device itself for higher-quality hardware or bigger batteries. But the home button was an important training exercise for what was a vastly more complex and capable mobile phone than consumers were used to. Like closing a clamshell phone, it was a safe, easy, and tactile way to ‘restart’ the iPhone if a user was confused or tapped the wrong app. It took a decade for consumers to be able to have no dedicated home button. This idea is critical. As time passes, consumers become increasingly familiar with advanced technology, and therefore better able to adopt further advances - some of which might have long been possible!
And just as consumers shift to new mindsets, so too does industry. Over the past 20 years, nearly every industry has hired, restructured, and re-oriented itself around mobile workflows, products, or business lines. This transformation is as significant as any hardware or software innovation — and, in turn, creates the business case for subsequent innovations.
Defining the Metaverse
This essay is the foreword to my nine-part and 33,000-word primer on the Metaverse, a term I’ve not yet mentioned, let alone described.
Before doing so, it was important for me to provide the context and evolutionary path of technologies such as ‘electricity’ and the ‘mobile internet’. Hopefully it provided a few lessons. First, the proliferation of these technologies fundamentally changed human culture, from where we lived to how we worked, what we made, what we bought, how, and from who. Second, these ‘revolutions’ or ‘transformations’ really depended on a bundle of many different, secondary innovations and inventions that built upon and drove one another. Third, even the most detailed understanding of these newly-emergent technologies didn’t make clear which specific, secondary innovations and inventions they required in order to achieve mass adoption and change the world. And how they would change the world was almost entirely unknowable.
In other words, we should not expect a single, all-illuminating definition of the ‘Metaverse’. Especially not at a time in which the Metaverse has only just begun to emerge. Technologically driven transformation is too organic and unpredictable of a process. Furthermore, it’s this very messiness that enables and results in such large-scale disruption.
My goal therefore is to explain what makes the Metaverse so significant – i.e. deserving of the comparisons I offered above – and offer ways to understand how it might work and develop.
The Metaverse is best understood as ‘a quasi-successor state to the mobile internet’. This is because the Metaverse will not fundamentally replace the internet, but instead build upon and iteratively transform it. The best analogy here is the mobile internet, a ‘quasi-successor state’ to the internet established from the 1960s through the 1990s. Even though the mobile internet did not change the underlying architecture of the internet – and in fact, the vast majority of internet traffic today, including data sent to mobile devices, is still transmitted through and managed by fixed infrastructure – we still recognize it as iteratively different. This is because the mobile internet has led to changes in how we access the internet, where, when and why, as well as the devices we use, the companies we patron, the products and services we buy, the technologies we use, our culture, our business model, and our politics.
The Metaverse will be similarly transformative as it too advances and alters the role of computers and the internet in our lives.
The fixed-line internet of the 1990s and early 2000s inspired many of us to purchase our own personal computer. However, this device was largely isolated to our office, living room or bedroom. As a result, we had only occasional access to and usage of computing resources and an internet connection. The mobile internet led most humans globally to purchase their own personal computer and internet service, which meant almost everyone had continuous access to both compute and connectivity.
Metaverse iterates further by placing everyone inside an ‘embodied’, or ‘virtual’ or ‘3D’ version of the internet and on a nearly unending basis. In other words, we will constantly be ‘within’ the internet, rather than have access to it, and within the billions of interconnected computers around us, rather than occasionally reach for them, and alongside all other users and real-time.
The progression listed above is a helpful way to understand what the Metaverse changes. But it doesn’t explain what it is or what it’s like to experience. To that end, I’ll offer my best swing at a definition:
“The Metaverse is a massively scaled and interoperable network of real-time rendered 3D virtual worlds which can be experienced synchronously and persistently by an effectively unlimited number of users with an individual sense of presence, and with continuity of data, such as identity, history, entitlements, objects, communications, and payments.”
Most commonly, the Metaverse is mis-described as virtual reality. In truth, virtual reality is merely a way to experience the Metaverse. To say VR is the Metaverse is like saying the mobile internet is an app. Note, too, that hundreds of millions are already participating in virtual worlds on a daily basis (and spending tens of billions of hours a month inside them) without VR/AR/MR/XR devices. As a corollary to the above, VR headsets aren’t the Metaverse any more than smartphones are the mobile internet.
Sometimes the Metaverse is described as a user-generated virtual world or virtual world platform. This is like saying the internet is Facebook or Geocities. Facebook is a UGC-focused social network on the internet, while Geocities made it easy to create webpages that lived on the internet. UGC experiences are just one of many experiences on the internet.
Furthermore, the Metaverse doesn’t mean a video game. Video games are purpose-specific (even when the purpose is broad, like ‘fun’), unintegrated (i.e. Call of Duty is isolated from fellow portfolio title Overwatch), temporary (i.e. each game world ‘resets’ after a match) and capped in participants (e.g. 1MM concurrent Fortnite users are in over 100,000 separated simulations. Yes, we will play games in the Metaverse, and those games may have user caps and resets, but those are games in the Metaverse, not the Metaverse itself. Overall, The Metaverse will significantly broaden the number of virtual experiences used in everyday life (i.e. well beyond video games, which have existed for decades) and in turn, expand the number of people who participate in them.
Lastly, the Metaverse isn’t tools like Unreal or Unity or WebXR or WebGPU. This is like saying the internet is TCP/IP, HTTP, or web browser. These are protocols upon which the internet depends, and the software used to render it.
The Metaverse, like the internet, mobile internet, and process of electrification, is a network of interconnected experiences and applications, devices and products, tools and infrastructure. This is why we don’t even say that horizontally and vertically integrated giants such as Facebook, Google or Apple are an internet. Instead, they are destinations and ecosystems on or in the internet, or which provide access to and services for the internet. And of course, nearly all of the internet would exist without them.
The Metaverse Emerges
As I’ve written before, the full vision of the Metaverse is decades away. It requires extraordinary technical advancements (we are far from being able to produce shared, persistent simulations that millions of users synchronized in real-time), and perhaps regulatory involvement too. In addition, it will require overhauls in business policies, and changes to consumer behavior.
But the term has become so recently popular because we can feel it beginning. This is one of the reasons why Fortnite and Roblox are so commonly conflated with the Metaverse. Just as the iPhone feels like the mobile internet because the device embodied the many innovations which enabled the mobile internet to go mainstream, these ‘games’ bring together many different technologies and trends to produce an experience which is simultaneously tangible and feels different from everything that came before. But they do not constitute the Metaverse.
Personally, I’m tracking the emergence of the Metaverse around eight core categories, which can be thought of as a stack (click each header for a dedicated essay).
Hardware: The sale and support of physical technologies and devices used to access, interact with, or develop the Metaverse. This includes, but is not limited to, consumer-facing hardware (such as VR headsets, mobile phones, and haptic gloves) as well as enterprise hardware (such as those used to operate or create virtual or AR-based environments, e.g. industrial cameras, projection and tracking systems, and scanning sensors). This category does not include compute-specific hardware, such as GPU chips and servers, as well as networking-specific hardware, such as fiber optic cabling or wireless chipsets.
Networking: The provisioning of persistent, real-time connections, high bandwidth, and decentralized data transmission by backbone providers, the networks, exchange centers, and services that route amongst them, as well as those managing ‘last mile’ data to consumers.
Compute: The enablement and supply of computing power to support the Metaverse, supporting such diverse and demanding functions as physics calculation, rendering, data reconciliation and synchronization, artificial intelligence, projection, motion capture and translation.
Virtual Platforms: The development and operation of immersive digital and often three-dimensional simulations, environments, and worlds wherein users and businesses can explore, create, socialize, and participate in a wide variety of experiences (e.g. race a car, paint a painting, attend a class, listen to music), and engage in economic activity. These businesses are differentiated from traditional online experiences and multiplayer video games by the existence of a large ecosystem of developers and content creators which generate the majority of content on and/or collect the majority of revenues built on top of the underlying platform.
Interchange Tools and Standards: The tools, protocols, formats, services, and engines which serve as actual or de facto standards for interoperability, and enable the creation, operation and ongoing improvements to the Metaverse. These standards support activities such as rendering, physics, and AI, as well as asset formats and their import/export from experience to experience, forward compatibility management and updating, tooling, and authoring activities, and information management.
Payments: The support of digital payment processes, platforms, and operations, which includes fiat on-ramps (a form of digital currency exchange) to pure-play digital currencies and financial services, including cryptocurrencies, such as bitcoin and ether, and other blockchain technologies.
Metaverse Content, Services, and Assets: The design/creation, sale, re-sale, storage, secure protection and financial management of digital assets, such as virtual goods and currencies, as connected to user data and identity. This contains all business and services “built on top of” and/or which “service” the Metaverse, and which are not vertically integrated into a virtual platform by the platform owner, including content which is built specifically for the Metaverse, independent of virtual platforms.
User Behaviors: Observable changes in consumer and business behaviors (including spend and investment, time and attention, decision-making and capability) which are either directly associated with the Metaverse, or otherwise enable it or reflect its principles and philosophy. These behaviors almost always seem like ‘trends’ (or, more pejoratively, ‘fads’) when they initially appear, but later show enduring global social significance.
(You’ll note ‘crypto’ or ‘blockchain technologies’ are not a category. Rather, they span and/or drive several categories, most notably compute, interchange tools and standards, and payments — potentially others as well.)
Each of these buckets is critical to the development of the Metaverse. In many cases, we have a good sense of how each one needs to develop, or at least where there’s a critical threshold (say, VR resolution and frame rates, or network latency).
But ultimately, how these many pieces come together and what they produce is the hard, important, and society-altering part of any Metaverse analysis. Just as the electricity revolution was about more than the kilowatt hours produced per square mile in 1900s New York, and the internet about more than HTTP and broadband cabling.
Based on precedent, however, we can guess that the Metaverse will revolutionize nearly every industry and function. From healthcare to payments, consumer products, entertainment, hourly labor, and even sex work. In addition, altogether new industries, marketplaces and resources will be created to enable this future, as will novel types of skills, professions, and certifications. The collective value of these changes will be in the trillions.
Is the time crystal really an otherworldly revolution, leveraging quantum computing that will change physics forever?
KEY TAKEAWAYS
Google’s quantum computing team, in a first, has developed and demonstrated a discrete time crystal on a quantum computer.
By driving the system with a microwave pulse, they can get it to return to its original quantum state periodically, with no thermal noise or decoherence effects.
However, claims that it violates thermodynamics, is otherworldly, or changes physics forever are all demonstrably untrue and misrepresentative of the actual quality research.
It is tempting, whenever a new discovery comes along, to imagine a whole slew of revolutions that might soon ensue. After all, anytime you can suddenly do or accomplish any task that was previously impractical or even (thought to be) impossible, that is one less obstacle standing in the way of even your loftiest, pie-in-the-sky dreams. However, no matter what discoveries ensue, the fundamental laws of physics that underlie reality must always be obeyed; you might be able to cajole nature into doing a lot of clever things, but you cannot very well break the rules that govern it. If you could, we would have to write down new laws, because the old ones would no longer be valid. Despite all the tricks we have developed, we cannot create fundamental magnetic monopoles, violate the conservation of momentum or energy, or work our way around the second law of thermodynamics.
Yet a recent article, touting a brand new discovery involving time crystals and Google’s quantum computer, claims to do just that: evade the second law of thermodynamics. Is that even right? Patreon supporter Chad Marler wants to know, asking:
Hi Ethan… I was reading some headlines and came across this article. While I suspect the innovation was real, some of the wording in the article made my [nonsense] detector go off… it sounds like something you would hear on an Art Bell show.
I will tell you, up front, that the scientific paper is legit, but the recent article is full of misconceptions and misinterpretations. Let’s dive in and find out what it is all about.
Normal crystals repeat their structure/configuration in space, like the crystal structure of corundum, α-Al2O3. But a time crystal would repeat its quantum state in time, instead. (Credit: Ben Mills)
What is a time crystal?
Unlike most things in physics, where theorists imagine a possibility far out of reach of current or near-future technology, time crystals have only been around for a very short time, even in our minds. In 2012, Nobel Laureate Frank Wilczek proposed that a new state of matter might exist: a time crystal. Most of us know what a normal crystal is: a repeating, rigid lattice or grid of particles, like atoms or molecules, that compose a solid, ordered structure.
When we talk about time crystals, however, there is no lattice, no grid, and no solid, ordered structure. The important component of a time crystal, at least conceptually, is the “repeating” part. Whereas a conventional crystal has a structure that repeats in space, meaning it exhibits translational symmetry (if you move within the crystal, the structure looks the same everywhere), a time crystal should repeat its configuration, periodically, in time.
Even in their ground state, electrons still have a non-zero energy, meaning that there will always be random motions over time. Only if the system returns to the exact original state, periodically, with no thermal noise or other imperfections, can a time crystal be created. (Credit: SPARKYSCIENCE AND ANTICOMPOSITENUMBER)
Originally, when time crystals were first considered, they were presumed to be impossible for a number of reasons. There were theorems published that proved their impossibility. There were assertions that a system that transitioned from lower-to-higher energy states would not return to its original state again spontaneously, and then go back-and-forth between those two states, because that would indicate some type of perpetual motion, violating the second law of thermodynamics and the conservation of energy.
But not only did theorists find loopholes in those theorems, but more impressively, experimentalists just went right ahead and created them in the lab. In 2016, Norman Yao and his team came up with a scheme to create a time crystal through a very clever plan. Instead of taking a closed, constant system, he proposed leveraging a system with out-of-equilibrium conditions. He would then “drive” that system externally, making it an open (rather than a closed) system and achieving the much sought after “time crystal” state.
Phase diagram of the discrete time crystal as a function of Ising interaction strength and spin-echo pulse imperfections. Only in the blue, shaded region is the time crystal state achieved, where the X-axis is the dipole spins (interaction strength) and the Y-axis is the driving force (pulses) injected into the system. (Credit: Norman Y. Yao, Andrew C. Potter, Ionut-Dragos Potirniche, Ashvin Vishwanath.)
It is a little bit complicated, but you can imagine that you have a bunch of atoms that have a spin, and those spins have directions: dipole moments. The way you can “drive” the system is by subjecting the system to spin-echo pulses that contain imperfections, but which occur periodically while allowing interactions to randomly occur in the intermediate times. If you get the combinations of these dipole moments of the spins and the spin-echo pulses to behave in a certain fashion, you could get a time crystal.
The hard part, though, is avoiding what normally happens when you interact with a system: If there is an exchange of energy, that energy gets transferred throughout the system, internally, causing runaway heating due to many-body interactions. Somehow, you have to:
drive the system, externally, with a spin-flip pulse,
so that you get a periodic response,
that is proportional to the time at which you pulse the system,
and at some multiple of the period, you return to your initial state,
while the “time crystal” only oscillates away from and then back into that initial state.
Only if you go back, periodically, to exactly your initial state, with no extra heating and achieve a pure steady-state can you make a time crystal.
The blueprint for creating a time crystal: take an entangled system and drive it with a spin-flip pulse. At some multiple of the period, you will return to the same initial state. (Credit: APS / Alan Stonebraker / Phil Richerme)
They tried to set up a system precisely as Yao had demanded but, because the conditions are so general, wound up taking vastly different approaches.
Monroe’s group took a series of yttrium atoms all lined up, in a one-dimensional line, all coupled together via their electrostatic interactions. When they subjected this atomic line to a series of spin-flip pulses, they found that the system would return to its initial state every two full pulse periods. Meanwhile, Lukin’s group took an actual diamond crystal that contained somewhere on the order of ~1,000,000 spin-impurities within it and pulsed those impurities within the crystal with microwave radiation. That radiation flipped their spins, but time crystal oscillations were only observed every three full pulse periods — whereupon the crystal would return to its initial quantum state.
The Harvard Diamond, created by a team led by Mikhail Lukin, has so many nitrogen impurities that it turned black. This is one of two independent physical systems used to create a time crystal. When driven under the proper conditions, it returns to its initial state, whatever that state may have been, every three full pulse periods. (Credit: Georg Kucsko.)
This occurred for both groups, interestingly enough, even when the driving pulses were imperfect. You could:
alter the magnitude of the pulse, making it stronger or weaker,
vary the frequency of pulsation, making it a little quicker or slower,
turn up or turn down the amount of noise and/or interactions that occurred between the pulses,
or change the conditions of the environment that the system is placed in,
and still recover this time crystal behavior. Surprisingly, for these non-equilibrium systems, there is a lot of wiggle-room as far as what you can do and still observe this time crystal behavior.
But as they were originally envisioned by Wilczek in 2012, an idealized time crystal would occur in a system that was in thermal equilibrium — that was neither absorbing nor emitting energy from or to the surrounding environment. In order to create a time crystal, you needed to have an open system that could exchange energy with its external surroundings, and that system needed to be driven at a periodic frequency. Moreover, the imperfections in the driving could not be too large, or the crystal would “melt” in precisely the fashion we want to avoid: with runaway heating occurring from many-body interactions.
Ten yttrium atoms with entangled electron spins, as used to first create a time crystal. With every two full pulse periods that pass, the full suite of atoms returns to its original, initial configuration of spins. (Credit: Chris Monroe, University of Maryland.)
What did the Google team, using a quantum computer, actually do?
Back when these time crystals were first realized in 2016/2017, it was recognized that time crystals could conceivably be applied to quantum computers. Instead of encoding a bit, like the “0” or “1” a standard computer encodes, a quantum computer encodes a qubit, which is a probability-weighted superposition of both “0” and “1” simultaneously. Although you can only measure a “0” or “1” at the end, the fact that you have many qubits allows you to see whether you have preserved the quantum behavior of the system (or not), whether your results are error-free (or not), and what type of final-state distribution you get and whether it matches your theoretical predictions.
The hard “problem” with a quantum computer is the problem of decoherence: Over relatively short timescales, the system interacts with the surrounding particles, and this causes you to lose the quantum behavior you are trying to preserve. For Google’s quantum computer, which is based on superconducting qubits (as opposed to quantum dots or ion traps, for example), you get a coherence timescale of about 50 microseconds. You can only perform perhaps a few dozen computations before decoherence ruins your experiment, and you lose the quantum behavior you sought to maintain and measure. (Or, more precisely, before too many errors, including errors from simple crosstalk between qubits, simply transform your signal into noise.)
The ordered and disordered eigenstates of a set of configurations. In equilibrium (a), only the lowest energy states are ordered, with higher-energy ones being unordered. In most driven systems (b), no states are ordered. But in systems with many-body localization (c), all states can be ordered, allowing for the possibility of returning periodically to your original state. (Credit: Google Quantum AI and collaborators, arXiv:2107.13571.)
Instead of using a dynamical phase like the spins of atoms, though, a quantum computer allows you to use a different property: the order of eigenstates in many-body systems. If you brought your qubits into an equilibrium setting, you would see that there was order in the lowest energy states and unordered states at higher energies. That is why, under normal circumstances, if you allow too much energy to propagate through your system, you just wind up with featureless, unordered systems; it is like the heat or energy just randomized everything.
However, some systems can exhibit what is called MBL: many-body localization, where you get local conservation laws and only a discrete number of ordered states. When you drive the system, which the Google team did with pulsed microwaves that cause the qubits to flip, your qubits have the potential to behave just like the dynamical phases did when we were measuring atomic spins: If the qubits do not absorb heat or impart energy to their surroundings, they can simply flip between different ordered states. With enough pulses, you can conceivably recover your original state.
Sure enough, every two full periods of the microwave pulses resulted in a recovery of the original state: a time crystal. Not bound by these decoherence effects any longer, the researchers could maintain this time crystal state for up to ~100 seconds, a remarkable achievement.
The Sycamore processor, which is a rectangular array of 54 qubits connected to its four nearest neighbros with couplers, contains one inoperable qubit, leading to an effective 53 qubit quantum computer. The optical image shown here illustrates the scale and color of the Sycamore chip as seen in optical light. (Credit: Google Quantum AI and collaborators, retrieved from NASA.)
Although the article does a fine job of describing the experiments performed themselves, there is a howler of a statement made early on:
With the ability to forever cycle between two states without ever losing energy, time crystals dodge one of the most important laws of physics — the second law of thermodynamics, which states that the disorder, or entropy, of an isolated system must always increase. These bizarre time crystals remain stable, resisting any dissolution into randomness, despite existing in a constant state of flux.
There is no dodge; the second law of thermodynamics applies to closed systems, not open ones. The disorder of the system, if you include the microwave pulses and the external environment, does in fact go up, just as predicted. The crystals oscillate between allowable states and return to their original ones when driven properly, just as their non-qubit analogues did years prior. In order to do this, the researchers needed to discriminate between external decoherence and internal thermalization, both of which can destroy the quantum state they are seeking to maintain, which itself is an admirable achievement.
When a series of food items are placed in a pan and the chef jiggles it in a way to coax the items into flipping, some will flip 180°, others 360°, others 540°, etc. But if the chef jiggles it enough times, all the items may return to their original state, rather than taking on random configurations. This is the concept of a time crystal. (Credit: Public domain / Creative Commons CC0.)
Although it may be fun to claim, as the headline of the article did, that this is “otherworldly” and “could change physics forever,” it is more like imagining you have got a skillet with different sized and shaped mollusks in it and a chef who jiggles the pan in a way that makes the shelled creatures flip. Some will flip 180°, others 360°, others 540°, etc. In the quantum world, some of these mollusks can take on in-between values, too. But after a certain number of jiggles, the mollusks all wind up the same way they started, regardless of what that specific initial configuration was. That is all the Google team is doing, but instead of mollusks or spinning atoms, they are using the eigenstates of a quantum computer.
Which, if we are being honest, is still a remarkable achievement! This is a new kind of time crystal, a new way of achieving it, and one with the potential to study non-equilibrium phases of matter on a quantum computer. And although you have to pump energy into the system in pulses, the time crystal can, in fact, return to whatever specific state it began with, even with small imperfections occurring in the “flips,” without destroying, decohering, or losing the nature of the quantum state due to thermal instabilities. No laws are violated and the physics we know is not changed in any way, but this is a phenomenal achievement nonetheless. In a mere nine years, we have gone from theorizing the existence of time crystals to creating them to observing them on a quantum processor. When a new field yields significant advances so quickly, it compels us to pay attention.
Information Security Attributes: or qualities, i.e., Confidentiality, Integrity and Availability (CIA). Information Systems are composed in three main portions, hardware, software and communications with the purpose to help identify and apply information security industry standards, as mechanisms of protection and prevention, at three levels or layers: physical, personal and organizational. Essentially, procedures or policies are implemented to tell administrators, users and operators how to use products to ensure information security within the organizations.[10]
Various definitions of information security are suggested below, summarized from different sources:
“Preservation of confidentiality, integrity and availability of information. Note: In addition, other properties, such as authenticity, accountability, non-repudiation and reliability can also be involved.” (ISO/IEC 27000:2009)[11]
“The protection of information and information systems from unauthorized access, use, disclosure, disruption, modification, or destruction in order to provide confidentiality, integrity, and availability.” (CNSS, 2010)[12]
“Ensures that only authorized users (confidentiality) have access to accurate and complete information (integrity) when required (availability).” (ISACA, 2008)[13]
“Information Security is the process of protecting the intellectual property of an organisation.” (Pipkin, 2000)[14]
“…information security is a risk management discipline, whose job is to manage the cost of information risk to the business.” (McDermott and Geer, 2001)[15]
“A well-informed sense of assurance that information risks and controls are in balance.” (Anderson, J., 2003)[16]
“Information security is the protection of information and minimizes the risk of exposing information to unauthorized parties.” (Venter and Eloff, 2003)[17]
“Information Security is a multidisciplinary area of study and professional activity which is concerned with the development and implementation of security mechanisms of all available types (technical, organizational, human-oriented and legal) in order to keep information in all its locations (within and outside the organization’s perimeter) and, consequently, information systems, where information is created, processed, stored, transmitted and destroyed, free from threats.[18] Threats to information and information systems may be categorized and a corresponding security goal may be defined for each category of threats.[19] A set of security goals, identified as a result of a threat analysis, should be revised periodically to ensure its adequacy and conformance with the evolving environment.[20] The currently relevant set of security goals may include: confidentiality, integrity, availability, privacy, authenticity & trustworthiness, non-repudiation, accountability and auditability.” (Cherdantseva and Hilton, 2013)[10]
Information and information resource security using telecommunication system or devices means protecting information, information systems or books from unauthorized access, damage, theft, or destruction (Kurose and Ross, 2010).[21]
Overview
At the core of information security is information assurance, the act of maintaining the confidentiality, integrity, and availability (CIA) of information, ensuring that information is not compromised in any way when critical issues arise.[22] These issues include but are not limited to natural disasters, computer/server malfunction, and physical theft. While paper-based business operations are still prevalent, requiring their own set of information security practices, enterprise digital initiatives are increasingly being emphasized,[23][24] with information assurance now typically being dealt with by information technology (IT) security specialists. These specialists apply information security to technology (most often some form of computer system). It is worthwhile to note that a computer does not necessarily mean a home desktop.[25] A computer is any device with a processor and some memory. Such devices can range from non-networked standalone devices as simple as calculators, to networked mobile computing devices such as smartphones and tablet computers.[26] IT security specialists are almost always found in any major enterprise/establishment due to the nature and value of the data within larger businesses.[27] They are responsible for keeping all of the technology within the company secure from malicious cyber attacks that often attempt to acquire critical private information or gain control of the internal systems.[28][29]
The field of information security has grown and evolved significantly in recent years.[30] It offers many areas for specialization, including securing networks and allied infrastructure, securing applications and databases, security testing, information systems auditing, business continuity planning, electronic record discovery, and digital forensics.[citation needed] Information security professionals are very stable in their employment.[31] As of 2013 more than 80 percent of professionals had no change in employer or employment over a period of a year, and the number of professionals is projected to continuously grow more than 11 percent annually from 2014 to 2019.[32]
Threats
Information security threats come in many different forms.[33][34] Some of the most common threats today are software attacks, theft of intellectual property, theft of identity, theft of equipment or information, sabotage, and information extortion.[35][36] Most people have experienced software attacks of some sort. Viruses,[37]worms, phishing attacks, and Trojan horses are a few common examples of software attacks. The theft of intellectual property has also been an extensive issue for many businesses in the information technology (IT) field.[38]Identity theft is the attempt to act as someone else usually to obtain that person’s personal information or to take advantage of their access to vital information through social engineering.[39][40] Theft of equipment or information is becoming more prevalent today due to the fact that most devices today are mobile,[41] are prone to theft and have also become far more desirable as the amount of data capacity increases. Sabotage usually consists of the destruction of an organization’s website in an attempt to cause loss of confidence on the part of its customers.[42] Information extortion consists of theft of a company’s property or information as an attempt to receive a payment in exchange for returning the information or property back to its owner, as with ransomware.[43] There are many ways to help protect yourself from some of these attacks but one of the most functional precautions is conduct periodical user awareness.[44] The number one threat to any organisation are users or internal employees, they are also called insider threats.[45]
Governments, military, corporations, financial institutions, hospitals, non-profit organisations, and private businesses amass a great deal of confidential information about their employees, customers, products, research, and financial status.[46] Should confidential information about a business’ customers or finances or new product line fall into the hands of a competitor or a black hat hacker, a business and its customers could suffer widespread, irreparable financial loss, as well as damage to the company’s reputation.[47] From a business perspective, information security must be balanced against cost; the Gordon-Loeb Model provides a mathematical economic approach for addressing this concern.[48]
For the individual, information security has a significant effect on privacy, which is viewed very differently in various cultures.[49]
Responses to threats
Possible responses to a security threat or risk are:[50]
reduce/mitigate – implement safeguards and countermeasures to eliminate vulnerabilities or block threats
assign/transfer – place the cost of the threat onto another entity or organization such as purchasing insurance or outsourcing
accept – evaluate if the cost of the countermeasure outweighs the possible cost of loss due to the threat[51]
History
Since the early days of communication, diplomats and military commanders understood that it was necessary to provide some mechanism to protect the confidentiality of correspondence and to have some means of detecting tampering.[52]Julius Caesar is credited with the invention of the Caesar cipher c. 50 B.C., which was created in order to prevent his secret messages from being read should a message fall into the wrong hands.[53] However, for the most part protection was achieved through the application of procedural handling controls.[54][55] Sensitive information was marked up to indicate that it should be protected and transported by trusted persons, guarded and stored in a secure environment or strong box.[56] As postal services expanded, governments created official organizations to intercept, decipher, read, and reseal letters (e.g., the U.K.’s Secret Office, founded in 1653[57]).
In the mid-nineteenth century more complex classification systems were developed to allow governments to manage their information according to the degree of sensitivity.[58] For example, the British Government codified this, to some extent, with the publication of the Official Secrets Act in 1889.[59] Section 1 of the law concerned espionage and unlawful disclosures of information, while Section 2 dealt with breaches of official trust.[60] A public interest defense was soon added to defend disclosures in the interest of the state.[61] A similar law was passed in India in 1889, The Indian Official Secrets Act, which was associated with the British colonial era and used to crack down on newspapers that opposed the Raj’s policies.[62] A newer version was passed in 1923 that extended to all matters of confidential or secret information for governance.[63] By the time of the First World War, multi-tier classification systems were used to communicate information to and from various fronts, which encouraged greater use of code making and breaking sections in diplomatic and military headquarters.[64] Encoding became more sophisticated between the wars as machines were employed to scramble and unscramble information.[65]
The establishment of computer security inaugurated the history of information security. The need for such appeared during World War II.[66] The volume of information shared by the Allied countries during the Second World War necessitated formal alignment of classification systems and procedural controls.[67] An arcane range of markings evolved to indicate who could handle documents (usually officers rather than enlisted troops) and where they should be stored as increasingly complex safes and storage facilities were developed.[68] The Enigma Machine, which was employed by the Germans to encrypt the data of warfare and was successfully decrypted by Alan Turing, can be regarded as a striking example of creating and using secured information.[69] Procedures evolved to ensure documents were destroyed properly, and it was the failure to follow these procedures which led to some of the greatest intelligence coups of the war (e.g., the capture of U-570[69]).
In 1973, important elements of ARPANET security were found by internet pioneer Robert Metcalfe to have many flaws such as the: “vulnerability of password structure and formats; lack of safety procedures for dial-up connections; and nonexistent user identification and authorizations”, aside from the lack of controls and safeguards to keep data safe from unauthorized access. Hackers had effortless access to ARPANET, as phone numbers were known by the public.[71] Due to these problems, coupled with the constant violation of computer security, as well as the exponential increase in the number of hosts and users of the system, “network security” was often alluded to as “network insecurity”.[71]
The end of the twentieth century and the early years of the twenty-first century saw rapid advancements in telecommunications, computing hardware and software, and data encryption.[72] The availability of smaller, more powerful, and less expensive computing equipment made electronic data processing within the reach of small business and home users.[73] The establishment of Transfer Control Protocol/Internetwork Protocol (TCP/IP) in the early 1980s enabled different types of computers to communicate.[74] These computers quickly became interconnected through the internet.[75]
The rapid growth and widespread use of electronic data processing and electronic business conducted through the internet, along with numerous occurrences of international terrorism, fueled the need for better methods of protecting the computers and the information they store, process, and transmit.[76] The academic disciplines of computer security and information assurance emerged along with numerous professional organizations, all sharing the common goals of ensuring the security and reliability of information systems.[citation needed]
The CIA triad of confidentiality, integrity, and availability is at the heart of information security.[77] (The members of the classic InfoSec triad—confidentiality, integrity, and availability—are interchangeably referred to in the literature as security attributes, properties, security goals, fundamental aspects, information criteria, critical information characteristics and basic building blocks.)[78] However, debate continues about whether or not this CIA triad is sufficient to address rapidly changing technology and business requirements, with recommendations to consider expanding on the intersections between availability and confidentiality, as well as the relationship between security and privacy.[22] Other principles such as “accountability” have sometimes been proposed; it has been pointed out that issues such as non-repudiation do not fit well within the three core concepts.[79]
The triad seems to have first been mentioned in a NIST publication in 1977.[80]
In 1992 and revised in 2002, the OECD‘s Guidelines for the Security of Information Systems and Networks[81] proposed the nine generally accepted principles: awareness, responsibility, response, ethics, democracy, risk assessment, security design and implementation, security management, and reassessment.[82] Building upon those, in 2004 the NIST‘s Engineering Principles for Information Technology Security[79] proposed 33 principles. From each of these derived guidelines and practices.
In information security, confidentiality “is the property, that information is not made available or disclosed to unauthorized individuals, entities, or processes.”[88] While similar to “privacy,” the two words aren’t interchangeable. Rather, confidentiality is a component of privacy that implements to protect our data from unauthorized viewers.[89] Examples of confidentiality of electronic data being compromised include laptop theft, password theft, or sensitive emails being sent to the incorrect individuals.[90]
Integrity
In IT security, data integrity means maintaining and assuring the accuracy and completeness of data over its entire lifecycle.[91] This means that data cannot be modified in an unauthorized or undetected manner.[92] This is not the same thing as referential integrity in databases, although it can be viewed as a special case of consistency as understood in the classic ACID model of transaction processing.[93] Information security systems typically incorporate controls to ensure their own integrity, in particular protecting the kernel or core functions against both deliberate and accidental threats.[94] Multi-purpose and multi-user computer systems aim to compartmentalize the data and processing such that no user or process can adversely impact another: the controls may not succeed however, as we see in incidents such as malware infections, hacks, data theft, fraud, and privacy breaches.[95]
More broadly, integrity is an information security principle that involves human/social, process, and commercial integrity, as well as data integrity. As such it touches on aspects such as credibility, consistency, truthfulness, completeness, accuracy, timeliness, and assurance.[96]
Availability
For any information system to serve its purpose, the information must be available when it is needed.[97] This means the computing systems used to store and process the information, the security controls used to protect it, and the communication channels used to access it must be functioning correctly.[98]High availability systems aim to remain available at all times, preventing service disruptions due to power outages, hardware failures, and system upgrades.[99] Ensuring availability also involves preventing denial-of-service attacks, such as a flood of incoming messages to the target system, essentially forcing it to shut down.[100]
In the realm of information security, availability can often be viewed as one of the most important parts of a successful information security program.[citation needed] Ultimately end-users need to be able to perform job functions; by ensuring availability an organization is able to perform to the standards that an organization’s stakeholders expect.[101] This can involve topics such as proxy configurations, outside web access, the ability to access shared drives and the ability to send emails.[102] Executives oftentimes do not understand the technical side of information security and look at availability as an easy fix, but this often requires collaboration from many different organizational teams, such as network operations, development operations, incident response, and policy/change management.[103] A successful information security team involves many different key roles to mesh and align for the CIA triad to be provided effectively.[104]
Non-repudiation
In law, non-repudiation implies one’s intention to fulfill their obligations to a contract. It also implies that one party of a transaction cannot deny having received a transaction, nor can the other party deny having sent a transaction.[105]
It is important to note that while technology such as cryptographic systems can assist in non-repudiation efforts, the concept is at its core a legal concept transcending the realm of technology.[106] It is not, for instance, sufficient to show that the message matches a digital signature signed with the sender’s private key, and thus only the sender could have sent the message, and nobody else could have altered it in transit (data integrity).[107] The alleged sender could in return demonstrate that the digital signature algorithm is vulnerable or flawed, or allege or prove that his signing key has been compromised.[108] The fault for these violations may or may not lie with the sender, and such assertions may or may not relieve the sender of liability, but the assertion would invalidate the claim that the signature necessarily proves authenticity and integrity. As such, the sender may repudiate the message (because authenticity and integrity are pre-requisites for non-repudiation).[109]
Broadly speaking, risk is the likelihood that something bad will happen that causes harm to an informational asset (or the loss of the asset).[110] A vulnerability is a weakness that could be used to endanger or cause harm to an informational asset. A threat is anything (man-made or act of nature) that has the potential to cause harm.[111] The likelihood that a threat will use a vulnerability to cause harm creates a risk. When a threat does use a vulnerability to inflict harm, it has an impact.[112] In the context of information security, the impact is a loss of availability, integrity, and confidentiality, and possibly other losses (lost income, loss of life, loss of real property).[113]
The Certified Information Systems Auditor (CISA) Review Manual 2006 defines risk management as “the process of identifying vulnerabilities and threats to the information resources used by an organization in achieving business objectives, and deciding what countermeasures,[114] if any, to take in reducing risk to an acceptable level, based on the value of the information resource to the organization.”[115]
There are two things in this definition that may need some clarification. First, the process of risk management is an ongoing, iterative process. It must be repeated indefinitely. The business environment is constantly changing and new threats and vulnerabilities emerge every day.[116] Second, the choice of countermeasures (controls) used to manage risks must strike a balance between productivity, cost, effectiveness of the countermeasure, and the value of the informational asset being protected.[117] Furthermore, these processes have limitations as security breaches are generally rare and emerge in a specific context which may not be easily duplicated.[118] Thus, any process and countermeasure should itself be evaluated for vulnerabilities.[119] It is not possible to identify all risks, nor is it possible to eliminate all risk. The remaining risk is called “residual risk.[120]“
A risk assessment is carried out by a team of people who have knowledge of specific areas of the business.[121] Membership of the team may vary over time as different parts of the business are assessed.[122] The assessment may use a subjective qualitative analysis based on informed opinion, or where reliable dollar figures and historical information is available, the analysis may use quantitative analysis.
Research has shown that the most vulnerable point in most information systems is the human user, operator, designer, or other human.[123] The ISO/IEC 27002:2005 Code of practice for information security management recommends the following be examined during a risk assessment:
Calculate the impact that each threat would have on each asset. Use qualitative analysis or quantitative analysis.[129]
Identify, select and implement appropriate controls. Provide a proportional response. Consider productivity, cost effectiveness, and value of the asset.[130]
Evaluate the effectiveness of the control measures. Ensure the controls provide the required cost effective protection without discernible loss of productivity.[131]
For any given risk, management can choose to accept the risk based upon the relative low value of the asset, the relative low frequency of occurrence, and the relative low impact on the business.[132] Or, leadership may choose to mitigate the risk by selecting and implementing appropriate control measures to reduce the risk. In some cases, the risk can be transferred to another business by buying insurance or outsourcing to another business.[133] The reality of some risks may be disputed. In such cases leadership may choose to deny the risk.[134]
Selecting and implementing proper security controls will initially help an organization bring down risk to acceptable levels.[135] Control selection should follow and should be based on the risk assessment.[136] Controls can vary in nature, but fundamentally they are ways of protecting the confidentiality, integrity or availability of information. ISO/IEC 27001 has defined controls in different areas.[137] Organizations can implement additional controls according to requirement of the organization.[138]ISO/IEC 27002 offers a guideline for organizational information security standards.[139]
Administrative
Administrative controls (also called procedural controls) consist of approved written policies, procedures, standards, and guidelines. Administrative controls form the framework for running the business and managing people.[140] They inform people on how the business is to be run and how day-to-day operations are to be conducted. Laws and regulations created by government bodies are also a type of administrative control because they inform the business.[141] Some industry sectors have policies, procedures, standards, and guidelines that must be followed – the Payment Card Industry Data Security Standard[142] (PCI DSS) required by Visa and MasterCard is such an example. Other examples of administrative controls include the corporate security policy, password policy, hiring policies, and disciplinary policies.[143]
Administrative controls form the basis for the selection and implementation of logical and physical controls. Logical and physical controls are manifestations of administrative controls, which are of paramount importance.[140]
Logical
Logical controls (also called technical controls) use software and data to monitor and control access to information and computing systems.[citation needed] Passwords, network and host-based firewalls, network intrusion detection systems, access control lists, and data encryption are examples of logical controls.[144]
An important logical control that is frequently overlooked is the principle of least privilege, which requires that an individual, program or system process not be granted any more access privileges than are necessary to perform the task.[145] A blatant example of the failure to adhere to the principle of least privilege is logging into Windows as user Administrator to read email and surf the web. Violations of this principle can also occur when an individual collects additional access privileges over time.[146] This happens when employees’ job duties change, employees are promoted to a new position, or employees are transferred to another department.[147] The access privileges required by their new duties are frequently added onto their already existing access privileges, which may no longer be necessary or appropriate.[148]
Physical
Physical controls monitor and control the environment of the work place and computing facilities.[149] They also monitor and control access to and from such facilities and include doors, locks, heating and air conditioning, smoke and fire alarms, fire suppression systems, cameras, barricades, fencing, security guards, cable locks, etc. Separating the network and workplace into functional areas are also physical controls.[150]
An important physical control that is frequently overlooked is separation of duties, which ensures that an individual can not complete a critical task by himself.[151] For example, an employee who submits a request for reimbursement should not also be able to authorize payment or print the check.[152] An applications programmer should not also be the server administrator or the database administrator; these roles and responsibilities must be separated from one another.[153]
Information security must protect information throughout its lifespan, from the initial creation of the information on through to the final disposal of the information.[154] The information must be protected while in motion and while at rest. During its lifetime, information may pass through many different information processing systems and through many different parts of information processing systems.[155] There are many different ways the information and information systems can be threatened. To fully protect the information during its lifetime, each component of the information processing system must have its own protection mechanisms.[156] The building up, layering on, and overlapping of security measures is called “defense in depth.”[157] In contrast to a metal chain, which is famously only as strong as its weakest link, the defense in depth strategy aims at a structure where, should one defensive measure fail, other measures will continue to provide protection.[158]
Recall the earlier discussion about administrative controls, logical controls, and physical controls. The three types of controls can be used to form the basis upon which to build a defense in depth strategy.[140] With this approach, defense in depth can be conceptualized as three distinct layers or planes laid one on top of the other.[159] Additional insight into defense in depth can be gained by thinking of it as forming the layers of an onion, with data at the core of the onion, people the next outer layer of the onion, and network security, host-based security, and application security forming the outermost layers of the onion.[160] Both perspectives are equally valid, and each provides valuable insight into the implementation of a good defense in depth strategy.[161]
An important aspect of information security and risk management is recognizing the value of information and defining appropriate procedures and protection requirements for the information.[162] Not all information is equal and so not all information requires the same degree of protection.[163] This requires information to be assigned a security classification.[164] The first step in information classification is to identify a member of senior management as the owner of the particular information to be classified. Next, develop a classification policy.[165] The policy should describe the different classification labels, define the criteria for information to be assigned a particular label, and list the required security controls for each classification.[166]
Some factors that influence which classification information should be assigned include how much value that information has to the organization, how old the information is and whether or not the information has become obsolete.[167] Laws and other regulatory requirements are also important considerations when classifying information.[168] The Information Systems Audit and Control Association (ISACA) and its Business Model for Information Security also serves as a tool for security professionals to examine security from a systems perspective, creating an environment where security can be managed holistically, allowing actual risks to be addressed.[169]
The type of information security classification labels selected and used will depend on the nature of the organization, with examples being:[166]
In the business sector, labels such as: Public, Sensitive, Private, Confidential.
In the government sector, labels such as: Unclassified, Unofficial, Protected, Confidential, Secret, Top Secret, and their non-English equivalents.[170]
In cross-sectoral formations, the Traffic Light Protocol, which consists of: White, Green, Amber, and Red.
All employees in the organization, as well as business partners, must be trained on the classification schema and understand the required security controls and handling procedures for each classification.[171] The classification of a particular information asset that has been assigned should be reviewed periodically to ensure the classification is still appropriate for the information and to ensure the security controls required by the classification are in place and are followed in their right procedures.[172]
Access control
Access to protected information must be restricted to people who are authorized to access the information.[173] The computer programs, and in many cases the computers that process the information, must also be authorized.[174] This requires that mechanisms be in place to control the access to protected information.[174] The sophistication of the access control mechanisms should be in parity with the value of the information being protected; the more sensitive or valuable the information the stronger the control mechanisms need to be.[175] The foundation on which access control mechanisms are built start with identification and authentication.[176]
Identification is an assertion of who someone is or what something is. If a person makes the statement “Hello, my name is John Doe” they are making a claim of who they are.[178] However, their claim may or may not be true. Before John Doe can be granted access to protected information it will be necessary to verify that the person claiming to be John Doe really is John Doe.[179] Typically the claim is in the form of a username. By entering that username you are claiming “I am the person the username belongs to”.[180]
Authentication
Authentication is the act of verifying a claim of identity. When John Doe goes into a bank to make a withdrawal, he tells the bank teller he is John Doe, a claim of identity.[181] The bank teller asks to see a photo ID, so he hands the teller his driver’s license.[182] The bank teller checks the license to make sure it has John Doe printed on it and compares the photograph on the license against the person claiming to be John Doe.[183] If the photo and name match the person, then the teller has authenticated that John Doe is who he claimed to be. Similarly, by entering the correct password, the user is providing evidence that he/she is the person the username belongs to.[184]
There are three different types of information that can be used for authentication:[185][186]
Strong authentication requires providing more than one type of authentication information (two-factor authentication).[192] The username is the most common form of identification on computer systems today and the password is the most common form of authentication.[193] Usernames and passwords have served their purpose, but they are increasingly inadequate.[194] Usernames and passwords are slowly being replaced or supplemented with more sophisticated authentication mechanisms such as Time-based One-time Password algorithms.[195]
Authorization
After a person, program or computer has successfully been identified and authenticated then it must be determined what informational resources they are permitted to access and what actions they will be allowed to perform (run, view, create, delete, or change).[196] This is called authorization. Authorization to access information and other computing services begins with administrative policies and procedures.[197] The policies prescribe what information and computing services can be accessed, by whom, and under what conditions. The access control mechanisms are then configured to enforce these policies.[198] Different computing systems are equipped with different kinds of access control mechanisms. Some may even offer a choice of different access control mechanisms.[199] The access control mechanism a system offers will be based upon one of three approaches to access control, or it may be derived from a combination of the three approaches.[90]
The non-discretionary approach consolidates all access control under a centralized administration.[200] The access to information and other resources is usually based on the individuals function (role) in the organization or the tasks the individual must perform.[201][202] The discretionary approach gives the creator or owner of the information resource the ability to control access to those resources.[200] In the mandatory access control approach, access is granted or denied basing upon the security classification assigned to the information resource.[173]
To be effective, policies and other security controls must be enforceable and upheld. Effective policies ensure that people are held accountable for their actions.[205] The U.S. Treasury‘s guidelines for systems processing sensitive or proprietary information, for example, states that all failed and successful authentication and access attempts must be logged, and all access to information must leave some type of audit trail.[206]
Also, the need-to-know principle needs to be in effect when talking about access control. This principle gives access rights to a person to perform their job functions.[207] This principle is used in the government when dealing with difference clearances.[208] Even though two employees in different departments have a top-secret clearance, they must have a need-to-know in order for information to be exchanged. Within the need-to-know principle, network administrators grant the employee the least amount of privilege to prevent employees from accessing more than what they are supposed to.[209] Need-to-know helps to enforce the confidentiality-integrity-availability triad. Need-to-know directly impacts the confidential area of the triad.[210]
Information security uses cryptography to transform usable information into a form that renders it unusable by anyone other than an authorized user; this process is called encryption.[211] Information that has been encrypted (rendered unusable) can be transformed back into its original usable form by an authorized user who possesses the cryptographic key, through the process of decryption.[212] Cryptography is used in information security to protect information from unauthorized or accidental disclosure while the information is in transit (either electronically or physically) and while information is in storage.[90]
Cryptography provides information security with other useful applications as well, including improved authentication methods, message digests, digital signatures, non-repudiation, and encrypted network communications.[213] Older, less secure applications such as Telnet and File Transfer Protocol (FTP) are slowly being replaced with more secure applications such as Secure Shell (SSH) that use encrypted network communications.[214] Wireless communications can be encrypted using protocols such as WPA/WPA2 or the older (and less secure) WEP. Wired communications (such as ITU‑TG.hn) are secured using AES for encryption and X.1035 for authentication and key exchange.[215] Software applications such as GnuPG or PGP can be used to encrypt data files and email.[216]
Cryptography can introduce security problems when it is not implemented correctly.[217] Cryptographic solutions need to be implemented using industry-accepted solutions that have undergone rigorous peer review by independent experts in cryptography.[218] The length and strength of the encryption key is also an important consideration.[219] A key that is weak or too short will produce weak encryption.[219] The keys used for encryption and decryption must be protected with the same degree of rigor as any other confidential information.[220] They must be protected from unauthorized disclosure and destruction, and they must be available when needed.[221]Public key infrastructure (PKI) solutions address many of the problems that surround key management.[90]
Process
The terms “reasonable and prudent person”, “due care“, and “due diligence” have been used in the fields of finance, securities, and law for many years. In recent years these terms have found their way into the fields of computing and information security.[125] U.S. Federal Sentencing Guidelines now make it possible to hold corporate officers liable for failing to exercise due care and due diligence in the management of their information systems.[222]
In the business world, stockholders, customers, business partners, and governments have the expectation that corporate officers will run the business in accordance with accepted business practices and in compliance with laws and other regulatory requirements. This is often described as the “reasonable and prudent person” rule. A prudent person takes due care to ensure that everything necessary is done to operate the business by sound business principles and in a legal, ethical manner. A prudent person is also diligent (mindful, attentive, ongoing) in their due care of the business.
In the field of information security, Harris[223] offers the following definitions of due care and due diligence:
“Due care are steps that are taken to show that a company has taken responsibility for the activities that take place within the corporation and has taken the necessary steps to help protect the company, its resources, and employees[224].” And, [Due diligence are the] “continual activities that make sure the protection mechanisms are continually maintained and operational.”[225]
Attention should be made to two important points in these definitions.[226][227] First, in due care, steps are taken to show; this means that the steps can be verified, measured, or even produce tangible artifacts.[228][229] Second, in due diligence, there are continual activities; this means that people are actually doing things to monitor and maintain the protection mechanisms, and these activities are ongoing.[230]
Organizations have a responsibility with practicing duty of care when applying information security. The Duty of Care Risk Analysis Standard (DoCRA)[231] provides principles and practices for evaluating risk.[232] It considers all parties that could be affected by those risks.[233] DoCRA helps evaluate safeguards if they are appropriate in protecting others from harm while presenting a reasonable burden.[234] With increased data breach litigation, companies must balance security controls, compliance, and its mission.[235]
Roles, responsibilities, and segregation of duties defined
Addressed and enforced in policy
Adequate resources committed
Staff aware and trained
A development life cycle requirement
Planned, managed, measurable, and measured
Reviewed and audited
Incident response plans
This section needs expansion. You can help by adding to it. (January 2018)
An incident response plan (IRP) is a group of policies that dictate an organizations reaction to a cyber attack. Once an security breach has been identified the plan is initiated.[237] It is important to note that there can be legal implications to a data breach. Knowing local and federal laws is critical.[238] Every plan is unique to the needs of the organization, and it can involve skill sets that are not part of an IT team.[239] For example, a lawyer may be included in the response plan to help navigate legal implications to a data breach.[240]
As mentioned above every plan is unique but most plans will include the following:[241]
Preparation
Good preparation includes the development of an Incident Response Team (IRT).[242] Skills need to be used by this team would be, penetration testing, computer forensics, network security, etc.[243] This team should also keep track of trends in cybersecurity and modern attack strategies.[244] A training program for end users is important as well as most modern attack strategies target users on the network.[241]
Identification
This part of the incident response plan identifies if there was a security event.[245] When an end user reports information or an admin notices irregularities, an investigation is launched. An incident log is a crucial part of this step.[246] All of the members of the team should be updating this log to ensure that information flows as fast as possible.[247] If it has been identified that a security breach has occurred the next step should be activated.[248]
Containment
In this phase, the IRT works to isolate the areas that the breach took place to limit the scope of the security event.[249] During this phase it is important to preserve information forensically so it can be analyzed later in the process.[250] Containment could be as simple as physically containing a server room or as complex as segmenting a network to not allow the spread of a virus.[251]
Eradication
This is where the threat that was identified is removed from the affected systems.[252] This could include using deleting malicious files, terminating compromised accounts, or deleting other components.[253][254] Some events do not require this step, however it is important to fully understand the event before moving to this step.[255] This will help to ensure that the threat is completely removed.[251]
Recovery
This stage is where the systems are restored back to original operation.[256] This stage could include the recovery of data, changing user access information, or updating firewall rules or policies to prevent a breach in the future.[257][258] Without executing this step, the system could still be vulnerable to future security threats.[251]
Lessons Learned
In this step information that has been gathered during this process is used to make future decisions on security.[259] This step is crucial to the ensure that future events are prevented. Using this information to further train admins is critical to the process.[260] This step can also be used to process information that is distributed from other entities who have experienced a security event.[261]
Change management is a formal process for directing and controlling alterations to the information processing environment.[262][263] This includes alterations to desktop computers, the network, servers, and software.[264] The objectives of change management are to reduce the risks posed by changes to the information processing environment and improve the stability and reliability of the processing environment as changes are made.[265] It is not the objective of change management to prevent or hinder necessary changes from being implemented.[266][267]
Any change to the information processing environment introduces an element of risk.[268] Even apparently simple changes can have unexpected effects.[269] One of management’s many responsibilities is the management of risk.[270][271] Change management is a tool for managing the risks introduced by changes to the information processing environment.[272] Part of the change management process ensures that changes are not implemented at inopportune times when they may disrupt critical business processes or interfere with other changes being implemented.[273]
Not every change needs to be managed.[274][275] Some kinds of changes are a part of the everyday routine of information processing and adhere to a predefined procedure, which reduces the overall level of risk to the processing environment.[276] Creating a new user account or deploying a new desktop computer are examples of changes that do not generally require change management.[277] However, relocating user file shares, or upgrading the Email server pose a much higher level of risk to the processing environment and are not a normal everyday activity.[278] The critical first steps in change management are (a) defining change (and communicating that definition) and (b) defining the scope of the change system.[279]
Change management is usually overseen by a change review board composed of representatives from key business areas,[280] security, networking, systems administrators, database administration, application developers, desktop support, and the help desk.[281] The tasks of the change review board can be facilitated with the use of automated work flow application.[282] The responsibility of the change review board is to ensure the organization’s documented change management procedures are followed.[283] The change management process is as follows[284]
Request: Anyone can request a change.[285][286] The person making the change request may or may not be the same person that performs the analysis or implements the change.[287][288] When a request for change is received, it may undergo a preliminary review to determine if the requested change is compatible with the organizations business model and practices, and to determine the amount of resources needed to implement the change.[289]
Approve: Management runs the business and controls the allocation of resources therefore, management must approve requests for changes and assign a priority for every change.[290] Management might choose to reject a change request if the change is not compatible with the business model, industry standards or best practices.[291][292] Management might also choose to reject a change request if the change requires more resources than can be allocated for the change.[293]
Plan: Planning a change involves discovering the scope and impact of the proposed change; analyzing the complexity of the change; allocation of resources and, developing, testing, and documenting both implementation and back-out plans.[294] Need to define the criteria on which a decision to back out will be made.[295]
Test: Every change must be tested in a safe test environment, which closely reflects the actual production environment, before the change is applied to the production environment.[296] The backout plan must also be tested.[297]
Schedule: Part of the change review board’s responsibility is to assist in the scheduling of changes by reviewing the proposed implementation date for potential conflicts with other scheduled changes or critical business activities.[298]
Communicate: Once a change has been scheduled it must be communicated.[299] The communication is to give others the opportunity to remind the change review board about other changes or critical business activities that might have been overlooked when scheduling the change.[300] The communication also serves to make the help desk and users aware that a change is about to occur.[301] Another responsibility of the change review board is to ensure that scheduled changes have been properly communicated to those who will be affected by the change or otherwise have an interest in the change.[302][303]
Implement: At the appointed date and time, the changes must be implemented.[304][305] Part of the planning process was to develop an implementation plan, testing plan and, a back out plan.[306][307] If the implementation of the change should fail or, the post implementation testing fails or, other “drop dead” criteria have been met, the back out plan should be implemented.[308]
Document: All changes must be documented.[309][310] The documentation includes the initial request for change, its approval, the priority assigned to it, the implementation,[311] testing and back out plans, the results of the change review board critique, the date/time the change was implemented,[312] who implemented it, and whether the change was implemented successfully, failed or postponed.[313][314]
Post-change review: The change review board should hold a post-implementation review of changes.[315] It is particularly important to review failed and backed out changes. The review board should try to understand the problems that were encountered, and look for areas for improvement.[315]
Change management procedures that are simple to follow and easy to use can greatly reduce the overall risks created when changes are made to the information processing environment.[316] Good change management procedures improve the overall quality and success of changes as they are implemented.[317] This is accomplished through planning, peer review, documentation, and communication.[318]
ISO/IEC 20000, The Visible OPS Handbook: Implementing ITIL in 4 Practical and Auditable Steps[319] (Full book summary),[320] and ITIL all provide valuable guidance on implementing an efficient and effective change management program information security.[321]
Business continuity
Business continuity management (BCM) concerns arrangements aiming to protect an organization’s critical business functions from interruption due to incidents, or at least minimize the effects.[322][323] BCM is essential to any organization to keep technology and business in line with current threats to the continuation of business as usual.[324] The BCM should be included in an organizations risk analysis plan to ensure that all of the necessary business functions have what they need to keep going in the event of any type of threat to any business function.[325]
It encompasses:
Analysis of requirements, e.g., identifying critical business functions, dependencies and potential failure points, potential threats and hence incidents or risks of concern to the organization;[326][327]
Specification, e.g., maximum tolerable outage periods; recovery point objectives (maximum acceptable periods of data loss);[328]
Architecture and design, e.g., an appropriate combination of approaches including resilience (e.g. engineering IT systems and processes for high availability,[329] avoiding or preventing situations that might interrupt the business), incident and emergency management (e.g., evacuating premises, calling the emergency services, triage/situation[330] assessment and invoking recovery plans), recovery (e.g., rebuilding) and contingency management (generic capabilities to deal positively with whatever occurs using whatever resources are available);[331]
Implementation, e.g., configuring and scheduling backups, data transfers, etc., duplicating and strengthening critical elements; contracting with service and equipment suppliers;
Testing, e.g., business continuity exercises of various types, costs and assurance levels;[332]
Management, e.g., defining strategies, setting objectives and goals; planning and directing the work; allocating funds, people and other resources; prioritization relative to other activities; team building, leadership, control, motivation and coordination with other business functions and activities[333] (e.g., IT, facilities, human resources, risk management, information risk and security, operations); monitoring the situation, checking and updating the arrangements when things change; maturing the approach through continuous improvement, learning and appropriate investment;[citation needed]
Assurance, e.g., testing against specified requirements; measuring, analyzing, and reporting key parameters; conducting additional tests, reviews and audits for greater confidence that the arrangements will go to plan if invoked.[334]
Whereas BCM takes a broad approach to minimizing disaster-related risks by reducing both the probability and the severity of incidents, a disaster recovery plan (DRP) focuses specifically on resuming business operations as quickly as possible after a disaster.[335] A disaster recovery plan, invoked soon after a disaster occurs, lays out the steps necessary to recover critical information and communications technology (ICT) infrastructure.[336] Disaster recovery planning includes establishing a planning group, performing risk assessment, establishing priorities, developing recovery strategies, preparing inventories and documentation of the plan, developing verification criteria and procedure, and lastly implementing the plan.[337]
Laws and regulations
Privacy International 2007 privacy ranking green: Protections and safeguards red: Endemic surveillance societies
Below is a partial listing of governmental laws and regulations in various parts of the world that have, had, or will have, a significant effect on data processing and information security.[338][339] Important industry sector regulations have also been included when they have a significant impact on information security.[338]
The UK Data Protection Act 1998 makes new provisions for the regulation of the processing of information relating to individuals, including the obtaining, holding, use or disclosure of such information.[340][341] The European Union Data Protection Directive (EUDPD) requires that all E.U. members adopt national regulations to standardize the protection of data privacy for citizens throughout the E.U.[342][343]
The Computer Misuse Act 1990 is an Act of the U.K. Parliament making computer crime (e.g., hacking) a criminal offense.[344] The act has become a model upon which several other countries,[345] including Canada and the Republic of Ireland, have drawn inspiration from when subsequently drafting their own information security laws.[346][347]
The E.U.’s Data Retention Directive (annulled) required internet service providers and phone companies to keep data on every electronic message sent and phone call made for between six months and two years.[348]
The Family Educational Rights and Privacy Act (FERPA) (20 U.S.C.§ 1232 g; 34 CFR Part 99) is a U.S. Federal law that protects the privacy of student education records.[349] The law applies to all schools that receive funds under an applicable program of the U.S. Department of Education.[350] Generally, schools must have written permission from the parent or eligible student[350][351] in order to release any information from a student’s education record.[352]
The Federal Financial Institutions Examination Council’s (FFIEC) security guidelines for auditors specifies requirements for online banking security.[353]
The Health Insurance Portability and Accountability Act (HIPAA) of 1996 requires the adoption of national standards for electronic health care transactions and national identifiers for providers, health insurance plans, and employers.[354] Additionally, it requires health care providers, insurance providers and employers to safeguard the security and privacy of health data.[355]
The Gramm–Leach–Bliley Act of 1999 (GLBA), also known as the Financial Services Modernization Act of 1999, protects the privacy and security of private financial information that financial institutions collect, hold, and process.[356]
Section 404 of the Sarbanes–Oxley Act of 2002 (SOX) requires publicly traded companies to assess the effectiveness of their internal controls for financial reporting in annual reports they submit at the end of each fiscal year.[357] Chief information officers are responsible for the security, accuracy, and the reliability of the systems that manage and report the financial data.[358] The act also requires publicly traded companies to engage with independent auditors who must attest to, and report on, the validity of their assessments.[359]
State security breach notification laws (California and many others) require businesses, nonprofits, and state institutions to notify consumers when unencrypted “personal information” may have been compromised, lost, or stolen.[364]
The Personal Information Protection and Electronics Document Act (PIPEDA) of Canada supports and promotes electronic commerce by protecting personal information that is collected, used or disclosed in certain circumstances,[365][366] by providing for the use of electronic means to communicate or record information or transactions and by amending the Canada Evidence Act, the Statutory Instruments Act and the Statute Revision Act.[367][368][369]
Greece’s Hellenic Authority for Communication Security and Privacy (ADAE) (Law 165/2011) establishes and describes the minimum information security controls that should be deployed by every company which provides electronic communication networks and/or services in Greece in order to protect customers’ confidentiality.[370] These include both managerial and technical controls (e.g., log records should be stored for two years).[371]
Greece’s Hellenic Authority for Communication Security and Privacy (ADAE) (Law 205/2013) concentrates around the protection of the integrity and availability of the services and data offered by Greek telecommunication companies.[372] The law forces these and other related companies to build, deploy, and test appropriate business continuity plans and redundant infrastructures.[373]
Information security culture
Describing more than simply how security aware employees are, information security culture is the ideas, customs, and social behaviors of an organization that impact information security in both positive and negative ways.[374] Cultural concepts can help different segments of the organization work effectively or work against effectiveness towards information security within an organization. The way employees think and feel about security and the actions they take can have a big impact on information security in organizations. Roer & Petric (2017) identify seven core dimensions of information security culture in organizations:[375]
Attitudes: Employees’ feelings and emotions about the various activities that pertain to the organizational security of information.[376]
Behaviors: Actual or intended activities and risk-taking actions of employees that have direct or indirect impact on information security.
Cognition: Employees’ awareness, verifiable knowledge, and beliefs regarding practices, activities, and self-efficacy relation that are related to information security.
Communication: Ways employees communicate with each other, sense of belonging, support for security issues, and incident reporting.
Compliance: Adherence to organizational security policies, awareness of the existence of such policies and the ability to recall the substance of such policies.
Norms: Perceptions of security-related organizational conduct and practices that are informally deemed either normal or deviant by employees and their peers, e.g. hidden expectations regarding security behaviors and unwritten rules regarding uses of information-communication technologies.
Responsibilities: Employees’ understanding of the roles and responsibilities they have as a critical factor in sustaining or endangering the security of information, and thereby the organization.
Andersson and Reimers (2014) found that employees often do not see themselves as part of the organization Information Security “effort” and often take actions that ignore organizational information security best interests.[377] Research shows information security culture needs to be improved continuously. In Information Security Culture from Analysis to Change, authors commented, “It’s a never ending process, a cycle of evaluation and change or maintenance.” To manage the information security culture, five steps should be taken: pre-evaluation, strategic planning, operative planning, implementation, and post-evaluation.[378]
Pre-Evaluation: to identify the awareness of information security within employees and to analyze current security policy
Strategic Planning: to come up a better awareness-program, we need to set clear targets. Clustering people is helpful to achieve it
Operative Planning: create a good security culture based on internal communication, management buy-in, security awareness, and training programs
Implementation: should feature commitment of management, communication with organizational members, courses for all organizational members, and commitment of the employees[378]
Post-evaluation: to better gauge the effectiveness of the prior steps and build on continuous improvement
The International Organization for Standardization (ISO) is a consortium of national standards institutes from 157 countries, coordinated through a secretariat in Geneva, Switzerland. ISO is the world’s largest developer of standards. ISO 15443: “Information technology – Security techniques – A framework for IT security assurance”, ISO/IEC 27002: “Information technology – Security techniques – Code of practice for information security management”, ISO-20000: “Information technology – Service management”, and ISO/IEC 27001: “Information technology – Security techniques – Information security management systems – Requirements” are of particular interest to information security professionals.
The US National Institute of Standards and Technology (NIST) is a non-regulatory federal agency within the U.S. Department of Commerce. The NIST Computer Security Division develops standards, metrics, tests, and validation programs as well as publishes standards and guidelines to increase secure IT planning, implementation, management, and operation. NIST is also the custodian of the U.S. Federal Information Processing Standard publications (FIPS).
The Internet Society is a professional membership society with more than 100 organizations and over 20,000 individual members in over 180 countries. It provides leadership in addressing issues that confront the future of the internet, and it is the organizational home for the groups responsible for internet infrastructure standards, including the Internet Engineering Task Force (IETF) and the Internet Architecture Board (IAB). The ISOC hosts the Requests for Comments (RFCs) which includes the Official Internet Protocol Standards and the RFC-2196 Site Security Handbook.
The Information Security Forum (ISF) is a global nonprofit organization of several hundred leading organizations in financial services, manufacturing, telecommunications, consumer goods, government, and other areas. It undertakes research into information security practices and offers advice in its biannual Standard of Good Practice and more detailed advisories for members.
The Institute of Information Security Professionals (IISP) is an independent, non-profit body governed by its members, with the principal objective of advancing the professionalism of information security practitioners and thereby the professionalism of the industry as a whole. The institute developed the IISP Skills Framework. This framework describes the range of competencies expected of information security and information assurance professionals in the effective performance of their roles. It was developed through collaboration between both private and public sector organizations, world-renowned academics, and security leaders.[379]
The German Federal Office for Information Security (in German Bundesamt für Sicherheit in der Informationstechnik (BSI)) BSI-Standards 100–1 to 100-4 are a set of recommendations including “methods, processes, procedures, approaches and measures relating to information security”.[380] The BSI-Standard 100-2 IT-Grundschutz Methodology describes how information security management can be implemented and operated. The standard includes a very specific guide, the IT Baseline Protection Catalogs (also known as IT-Grundschutz Catalogs). Before 2005, the catalogs were formerly known as “IT Baseline Protection Manual”. The Catalogs are a collection of documents useful for detecting and combating security-relevant weak points in the IT environment (IT cluster). The collection encompasses as of September 2013 over 4,400 pages with the introduction and catalogs. The IT-Grundschutz approach is aligned with to the ISO/IEC 2700x family.
HACKTOPIA is een nieuw citizen science-initiatief van de stad Antwerpen en Vlaams onderzoekscentrum imec . Via deze ‘open call’ nodigen we burgers uit om actief mee na te denken over de problematiek van wateroverlast in de stad Antwerpen. Welke uitdagingen kunnen worden aangepakt? Jullie komen zelf met het idee, wij zoeken mee naar de juiste technologie en data om de stad te ‘hacken’, bottom-up te verbeteren. Iedereen (burger) wetenschapper!
HACKTOPIA
HACKTOPIA is een initiatief van de Stad Antwerpen en Vlaams onderzoekscentrum imec waarbij we burgers empoweren om de slimme stad van morgen vorm te geven. Jij komt met het idee, wij reiken de technologie en data aan om de stad zelf te ‘hacken’.
Deze editie van HACKTOPIA heeft als thema WATER, en dan meer bepaald de problemen en vraagstukken die hierbij komen kijken. Hevige regenval of stormweer kan een heleboel water met zich meebrengen. Misschien vind je dat klimaatadaptatie nét niet snel genoeg gaat, of heb je zelfs al een straf idee over wat een stad als Antwerpen juist nodig heeft. Zie jij de last in wateroverlast?
Schotel ons dan jouw op te lossen watervraagstukken voor… en wie weet steken jij en Anthony Liekens (zelfverklaarde ‘mad scientist’ met een missie: wetenschap en technologie voor iedereen toegankelijk maken) van Makerspace Antwerpen binnenkort de handen uit de mouwen om ’t stad te hacken!
Mad scientist Anthony Liekens
What the Hack?!
Stap 1 Je broedt op een idee of een uitdaging die je graag aangepakt ziet. Waaraan moet jouw idee of uitdaging voldoen?
het thema wateroverlast staat centraal
het is gebaseerd op een reële nood van (de inwoners van) Antwerpen
het is relevant voor een groot aantal burgers van de stad (niet enkel voor jou)
er zit een innovatief en – bij voorkeur – technologisch kantje aan
het is een duurzame oplossing die na afloop van het project nog een eigen leven kan leiden
Stap 2 Je zendt het idee in via onderstaand formulier. We contacteren je binnen de paar dagen om een telefonisch intakegesprek met ons te voeren.
Stap 3 Vanaf nu wordt het echt spannend! Je wordt misschien wel geselecteerd om je concept samen met ons verder te ontwikkelen.
Stap 4 Jij en je eventuele mede-makers nemen deel aan een aantal workshops (meer info hieronder). Professionele makers van Makerspace Antwerpen en experten van onder andere imec staan je bij met raad en daad om je idee vorm te geven en een blauwdruk te ontwikkelen .
Stap 5 De makers gaan samen met jou aan de slag om een simulatie van je oplossing te bouwen. Dit vroege prototype gaan we dan ‘in het echt’ testen met (eind)gebruikers.
Stap 6 Na een spannend jury-event wordt het beste concept uitgekozen voor een vervolgtraject. Daarbij wordt je oplossing verder uitgewerkt tot een eerste werkend prototype (proof of concept). Ben je nieuwsgierig naar wat dit juist inhoudt? Lees dan zeker ook de GitHub-pagina van Klankentappers, het winnende imec Hackable City of Things, citizen science concept uit 2019!
Bij selectie contacteren we je om een telefonisch intakegesprek in te plannen.
Tijdens dit gesprek evalueren we jouw idee aan de hand van de vooropgestelde selectiecriteria (zie: stap 1).
Na je eventuele selectie ontvang je nog een uitgebreidere briefing met wat je juist kan verwachten .
Voorwaarden
Je engageert je om bij deelname:
Te werken binnen een team van minimaal 3 en maximaal 6 personen. Het team wordt na selectie gevormd door imec en stad Antwerpen op basis van gelijkaardige uitdagingen en ideeën.
Deelnemers die in groep inschrijven (max. 3 personen) worden bij selectie automatisch in hetzelfde team geplaatst.
Het volledige proces te doorlopen, en deel te nemen aan alle workshops.
Actief bij te dragen aan het maken van het prototype en het uitvoeren van de test.
Je oplossing en de data die daar eventueel uit voortvloeien open te stellen voor je medeburgers, onderzoekers en de stad.
Wat staat je te wachten?
Gedurende het onderzoeksproject word je ondersteund door een innovatiemanager van imec en een maker van Makerspace Antwerpen. Bovendien kan je steunen op het advies van experts van stad Antwerpen, imec en eventuele derde partijen.
De workshops vinden telkens plaats op een donderdagavond na de werkuren (met uitzondering van de testingdag), en dit op volgende data:
Lees meer over Klankentappers, dit citizen-scienceproject wil wetenschappelijk onderbouwde geluidsmetingen betaalbaar en toegankelijk maken voor burgers.




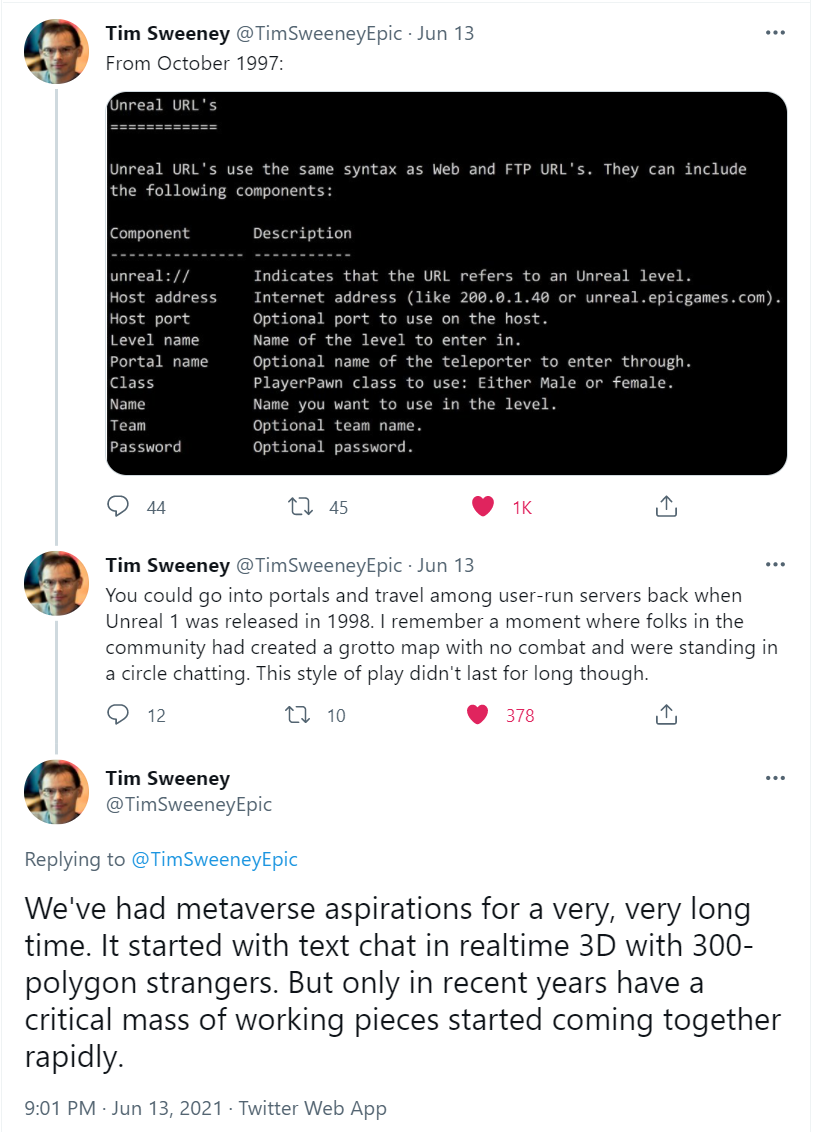
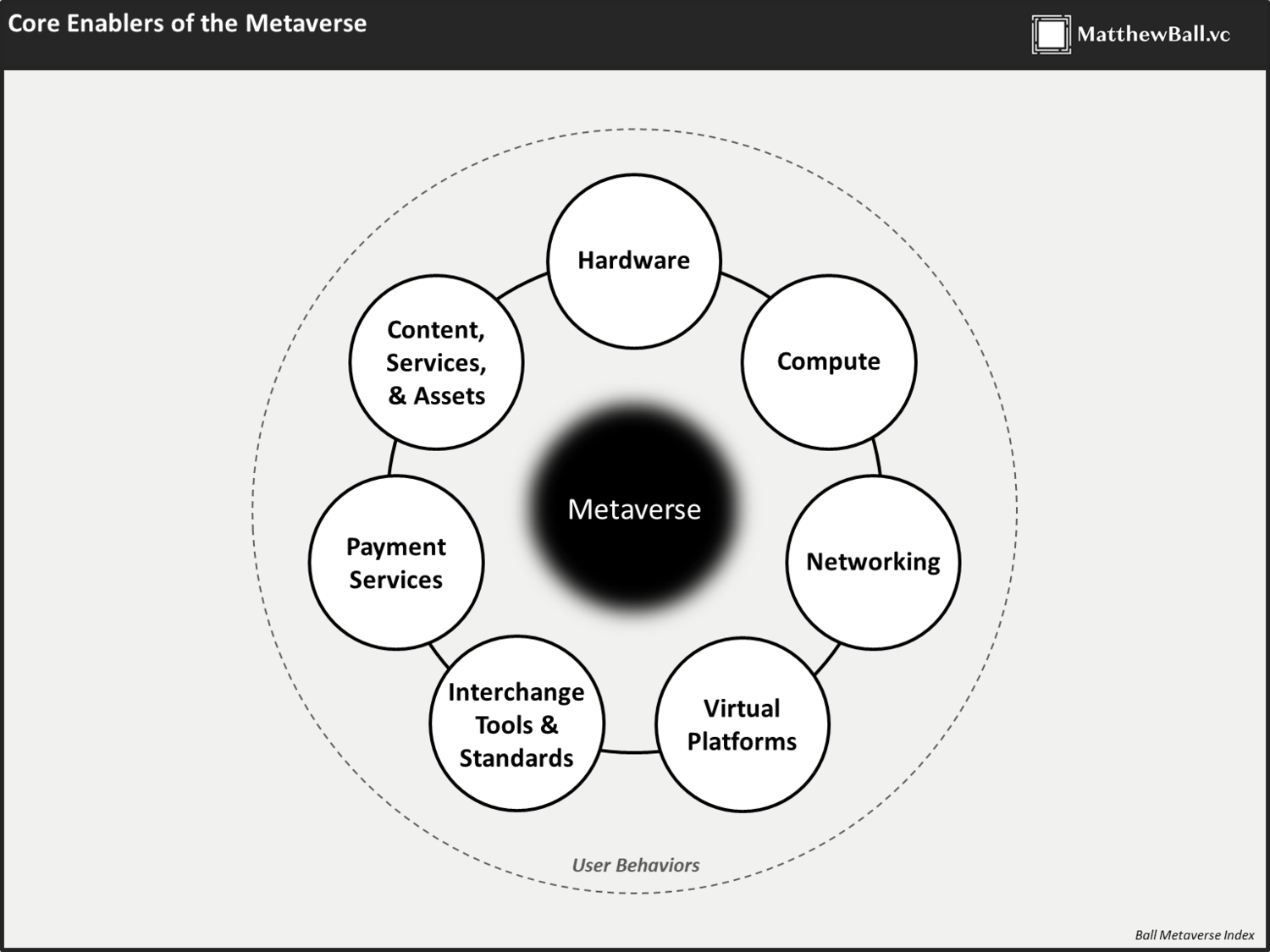


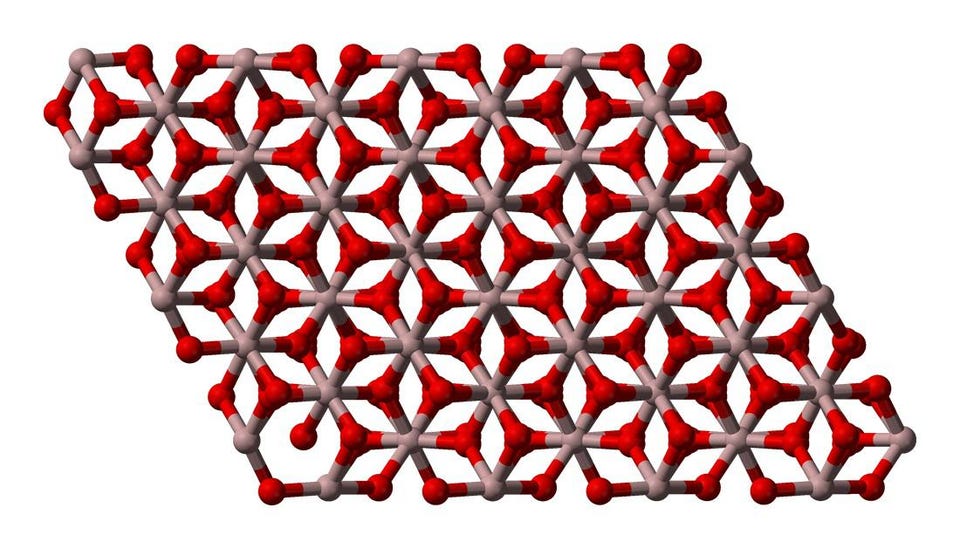
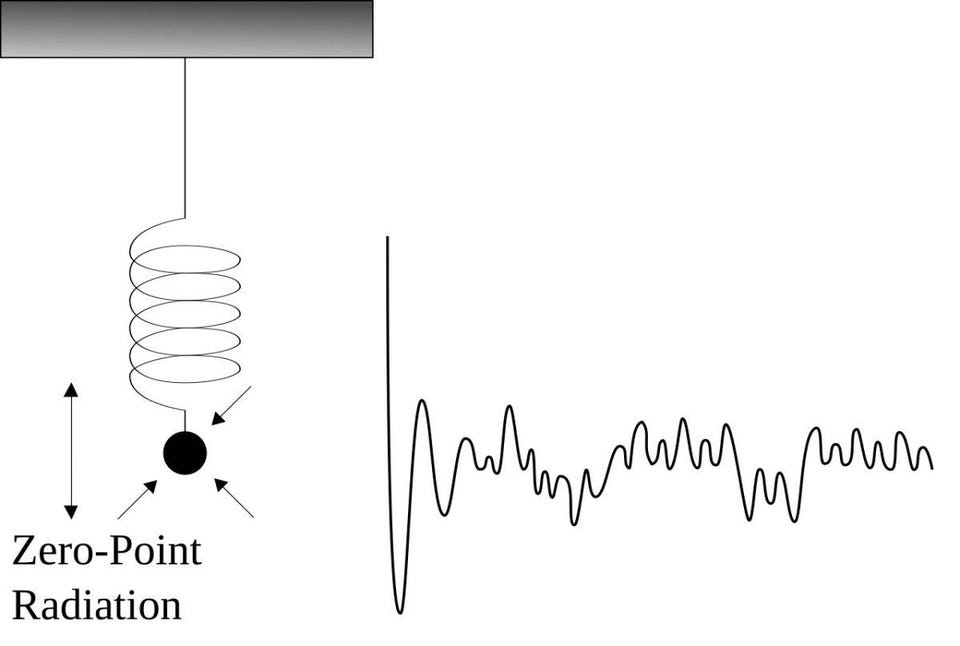
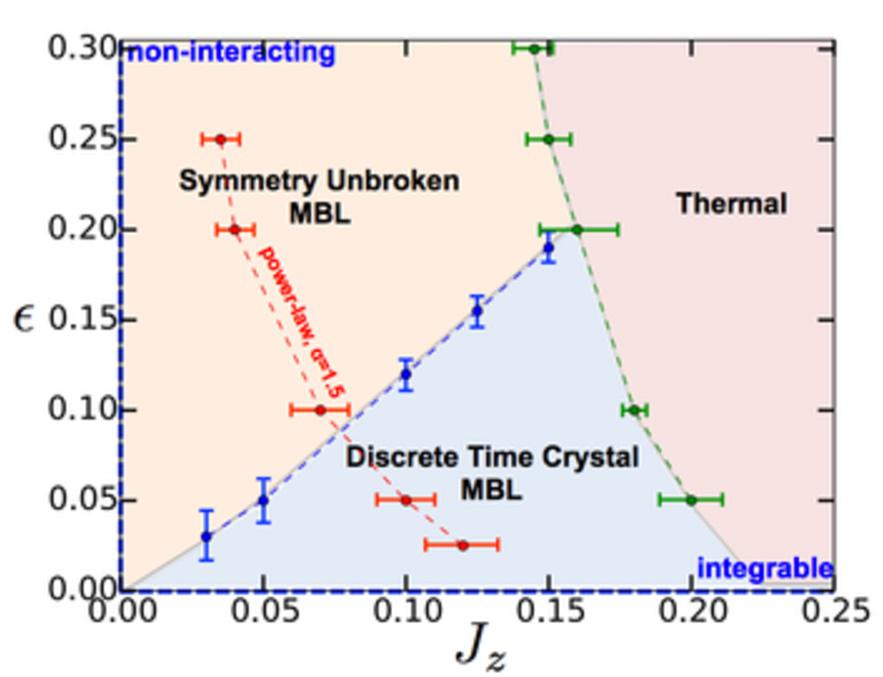
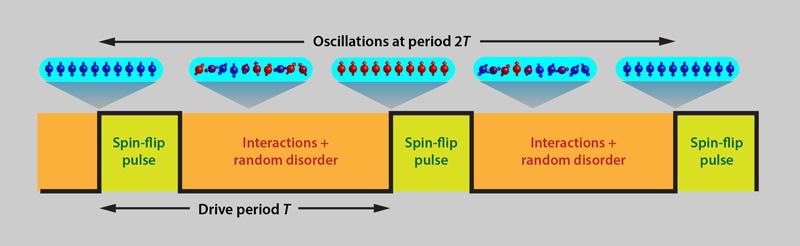

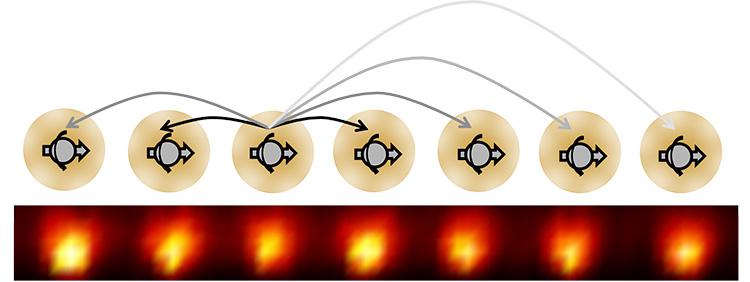
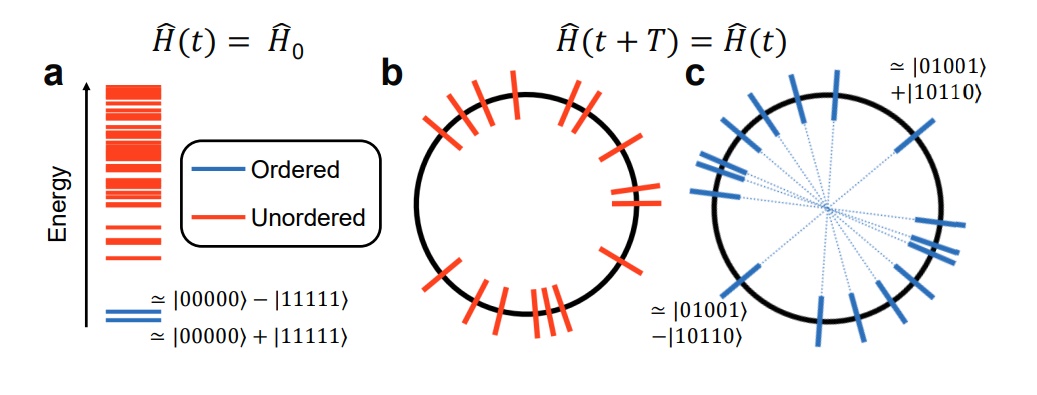




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
You must be logged in to post a comment.