According to the concept of sociology and philosophy hive mind are the collective consciousness and collective intelligence. It is most familiar term in science fiction. Through hive mind, everyone would be connected to everyone else telepathically and we could share our thoughts, memories even dreams. Though a global hive mind would be susceptible to things like hacking or thought control, it could also lead to almost unimaginable levels of innovation. Many researchers buckling down to connect human brains to communicate using this hive mind concept.
First successful demonstration of the brain to brain communication in human was done in 2014 by neuroscientists. The experiment allowed the subjects to exchange mentally conjured despite being 5,000 miles apart. It’s the neuroscientific equivalent of instant messaging. Two human subjects, one in India and one in France, successfully transmitted the words “hola” and “ciao” in a computer-assisted brain-to-brain transmission using internet-linked electroencephalogram (EEG) and robot-assisted image-guided transcranial magnetic stimulation (TMS) technologies.
To this experiment, Researchers used EEG technology to make interconnection of one human mind to another human mind. They recruited four participants, one of whom was assigned to the brain-computer interface (BCI) branch, the part of the chain where the messages were to originate. The other three participants were assigned to the computer-brain interface (CBI) branch to receive the messages being transmitted to them.
Using EEG, the researchers translated the greetings “hola” and “ciao” into binary, and then emailed the results from India to France. At this receiving location, a CBI transmitted the message to the receivers’ brains through noninvasive brain stimulation. This was experienced as phosphenes — flashes of light in their peripheral vision. The light appeared in the numerical sequences that allowed the receivers to decode the data in the message. It’s important to note that this information was not conveyed to the subjects via tactile, visual, or auditory cues; special measures were taken to block sensory input. This ensured that the communication was exclusively mind-to-mind — though it was channeled through several different mediums.
A second experiment was conducted between individuals in Spain and France, achieving a total error rate of just 15% percent (11% on the decoding end and 5% on the initial coding site).
This in itself is a remarkable step in human communication, but being able to do so across a distance of thousands of miles is a critically important proof-of-principle for the development of brain-to-brain communications.
Alternatively, we can say that hive mind is the apparent intelligence that emerges at the group level in some social species, particular insects like honeybees and ants. An individual honeybee might not be very bright (although that’s debatable), but the honeybee colony as a collective might be very intelligent.
Other works on hive mind:
Google hive mind robot:
Google’s electrical engineer Sergey Levine has published a paper on ArXiv about the developments the team has made in creating deep learning software that tries to mimic humans picking up objects. Levine and his fellow researchers have decided that the best option is to hook up 14 robots to a hive mind – like the Borg race in Star Trek – and force them to pick up objects over and over again.
Once one of them figures out how to pick up a particular object, it will pass on the information to the others in the neural network.
Observing the behavior of the arms over 800,000 grasp attempts, the researchers have shown no major improvement in terms of their ability to pick up objects in a more human-like manner, but their decisions in how they pick things up – such as where is the best place to grasp it – has reached almost human levels.
Scientists from MIT’s Sloan Neuroeconomics Lab and Princeton University decided to look for a better way to harvest the boundless potential of the hive mind. Through their research, which is published in the journal “Nature”, they were able to develop a technique that they dubbed the “surprisingly popular” algorithm. This algorithm can more accurately pinpoint correct answers from large groups of people through a rather simple technique. People are asked a question, and they must give two answers. The first is what they think the correct answer is, and the second is what they think the popular opinion will be. The overall deviation between the crowd’s two responses indicates the correct answer.
In the future, the scientists hope to utilize their method in a number of different settings, such as political forecasting, making economic predictions, pricing artwork, or grading research proposals.
One day soon, the hive mind may be used as the primary way for us to make predictions and prepare for whatever the future holds.
Genomic surveillance in Belgium is based on whole genome sequencing (WGS) of a selection of representative samples, complemented with targeted active surveillance initiatives and targeted molecular markers aiming to early detect and precisely monitor the epidemiological evolution of variants of concern (VOCs). Currently, 5.050 sequences of samples collected in Belgium are available on GISAID in open access. During week 3 of 2021, Belgium achieved a coverage of 3,5% of all positive sequences being sequenced. During the last 2 weeks (week 5 and 6), 146 samples have been sequenced as part of the baseline surveillance, among which 48 (33%) were 501Y.V1 and 8 (5%) were 501Y.V2. Since week 52 of 2020, Belgium has experienced multiple introductions of VOCs followed by sustained local transmissions. As a consequence of a higher transmissibility of these variants, we observe a progressive shift in viral populations, with 501Y.V1 expected to represent the majority of circulating strains by early March. Together with the rollout of vaccination, genomic surveillance will monitor the eventual positive selection of VOCs harbouring immune escape mutations such as S:E484K. During the last 2 weeks, the progressive phenomenon of viral population replacement by more transmissible strains did not alter the overall stability of the epidemic in Belgium. This is probably due to a combination of active public health response and limited number of social interactions in the population. The risk of disruption of this equilibrium remains, as the proportion of more transmissible viruses will continue rising, but this risk can be mitigated by a combination of active outbreak control interventions, maintained efforts to reduce transmission in the population and rapid roll-out of vaccination.
The neural network behind big language processors is creeping into other corners of AI
Transformers, the type of neural network behind OpenAI’s GPT-3 and other big natural-language processors, are quickly becoming some of the most important in industry, and they are likely to spread to other—perhaps all—areas of AI. Nvidia’s new Hopper H100 is proof that the leading maker of chips for accelerating AI is a believer. Among the many architectural changes that distinguish the H100 from its predecessor, the A100, is a “transformer engine.” Not a distinct part of the new hardware exactly, it’s a way of dynamically changing the precision of the calculations in the cores to speed up the training of transformer neural networks.
“One of the big trends in AI is the emergence of transformers,” says Dave Salvator, senior product manager for AI inference and cloud at Nvidia. Transformers quickly took over language AI, because their networks pay “attention” to multiple sentences, enabling them to grasp context and antecedents. (The T in the benchmark language model BERT stands for “transformer” as it does in the occasionally insultingGPT-3.)
“We are trending very quickly toward trillion parameter models” —Dave Salvator, Nvidia
But more recently, researchers have been seeing an advantage to applying that same sense of attention to vision and other models dominated by convolutional neural networks. Salvator notes that more than two-thirds of papers about neural networks in the last two years dealt with transformers or their derivatives. “The number of challenges transformers can take on continues to grow,” he says.
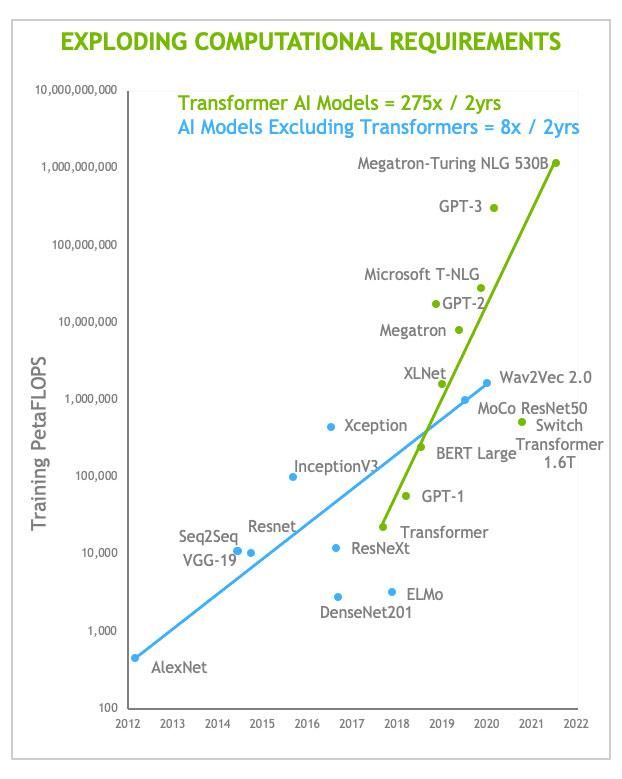
However, transformers are among the biggest neural-network models in terms of the number of parameters involved. And they are growing much faster than other models. “We are trending very quickly toward trillion-parameter models,” says Salvator. Nvidia’s analysis shows the training needs of transformer models growing 275-fold every two years, while the trend for all other models is 8-fold growth every two years. Bigger models need more computational resources especially for training, but also for operating in real time as they often need to do. Nvidia developed the transformer engine to help keep up.
The computational needs of transformers are growing more rapidly than those of other forms of AI. Those are growing really fast, too, of course.NVIDIA
The transformer engine is really software combined with new hardware capabilities in Hopper’s tensor cores. These are the units dedicated to carrying out machine learning’s bread-and-butter calculation—matrix multiply and accumulate. Hopper has tensor cores capable of computing with floating-point numbers of a variety of precision—from 64-bit down to 8-bit. The A100’s cores were designed for floating-point numbers only as short as 16 bits. But the trend in AI computing has been toward developing neural nets that lean on the lowest precision that will still yield an accurate result. The smaller formats compute faster and more efficiently, and they require less memory and memory bandwidth. The addition of 8-bit floating-point units in the H100 leads to a significant speedup—double the throughput compared to its 16-bit units.
The transformer engine’s secret sauce is its ability to dynamically choose what precision is needed for each layer in the neural network at each step in training a neural network. The least-precise units, the 8-bit floating point, can speed through their computations, but then produce 16-bit or 32-bit sums for the next layer if that’s the precision needed there. The Hopper goes a step further, though. Its 8-bit floating-point units can do their matrix math with either of two forms of 8-bit numbers.
To understand why that’s helpful, you might need a quick lesson in the structure of floating-point numbers. This format represents numbers using some of the bits for the exponent, some for the mantissa, and one for the sign. The more bits you have representing the exponent, the greater the range of numbers you can express. The more bits in the mantissa, the greater the precision of those numbers. The standard 16-bit floating-point format (IEEE 754-2008) demands 5 bits of exponent and 10 bits of mantissa, along with the sign bit. Seeking to reduce data-storage requirements and speed machine learning, makers of AI accelerators recently adopted bfloat-16, which trades three bits of mantissa for an added exponent, giving it the same range as a 32-bit number.
Nvidia has taken that trade-off further. “One of the unique things we found when you get to [8-bit] is that there really isn’t a one size fits all format that we were confident would work,” says Jonah Alben, Nvidia’s senior vice president of GPU engineering. So Hopper’s 8-bit units can work with either 5 bits of exponent and two of mantissa (E5M2) when range is important or 4 bits of exponent and three of mantissa (E4M3) when precision is key. The transformer engine orchestrates what’s needed on the fly to speed training. We “embody our experience testing transformers into this so that it knows how to make the right decisions,” says Alben.
In practice, this usually means using different types of floating-point formats for the different parts of a training task. Generally, training a neural network involves exposing it to lots of data (forward inferencing), measuring how bad the network is at doing its task on that data, and then adjusting the network parameters, layer-by-layer backwards through the network to improve it (back propagation). Wash, rinse, repeat. Generally, back propagation needs greater precision, so the E4M3 format might be favored there, while the inferencing (forward) step favors the E5M3’s range.
I first wrote about the Metaverse in 2018, and overhauled my thinking in a January 2020 update: The Metaverse: What It Is, Where to Find it, Who Will Build It, and Fortnite. Since then, a lot has happened. COVID-19 forced hundreds of millions into Zoomschool and remote work. Roblox became one of the most popular entertainment experiences in history. Google Trends’ index on the phrase ‘The Metaverse’ set a new ‘100’ in March 2021. Against this baseline, use of the term never exceeded seven from January 2005 through to December 2020. With that in mind, I thought it was time to do an update - one that reflects how my thinking has changed over the past 18 months and addresses the questions I’ve received during this time, such as “Is the Metaverse here?”, “When will it arrive?”, and “What does it need to grow?”. Welcome to the Foreword to ‘THE METAVERSE PRIMER’.
When did the mobile internet era begin? Some would start this history with the very first mobile phones. Others might wait until the commercial deployment of 2G, which was the first digital wireless network. Or the introduction of the Wireless Application Protocol standard, which gave us WAP browsers and thus the ability to access a (rather primitive) version of most websites from nearly any ‘dumbphone’. Or maybe it started with the BlackBerry 6000, or 7000 or 8000 series? At least one of them was the first mainstream mobile device designed for on-the-go data. Most would say it’s the iPhone, which came more than a decade after the first BlackBerry and eight years after WAP, nearly two decades after 2G, 34 years after the first mobile phone call, and has since defined many of the mobile internet era’s visual design principles, economics, and business practices.
In truth, there’s never a flip. We can identify when a specific technology was created, tested, or deployed, but not when an era precisely occurred. This is because technological change requires a lot of technological changes, plural, to all come together. The electricity revolution, for example, was not a single period of steady growth. Instead, it was two separate waves of technological, industrial, and process-related transformations.
The first wave began around 1881, when Thomas Edison stood up electric power stations in Manhattan and London. Although this was a quick start to the era of electrical power — Edison had created the first working incandescent light bulb only two years earlier, and was only one year into its commercialization — industrial adoption was slow. Some 30 years after Edison’s first stations, less than 10% of mechanical drive power in the United States came from electricity (two thirds of which was generated locally, rather than from a grid). But then suddenly, the second wave began. Between 1910 and 1920, electricity’s share of mechanical drive power quintupled to over 50% (nearly two thirds of which came from independent electric utilities. By 1929 it stood at 78%).
The difference between the first and second waves is not how much of American industry used electricity, but the extent to which it did — and designed around it.
When plants first adopted electrical power, it was typically used for lighting and/or to replace a plant’s on-premises source of power (usually steam). These plants did not, however, rethink or replace the legacy infrastructure which would carry this power throughout the factory and put it to work. Instead, they continued to use a lumbering network of cogs and gears that were messy and loud and dangerous, difficult to upgrade or change, were either ‘all on’ or ‘all off’ (and therefore required the same amount of power to support a single operating station or the entire plant, and suffered from countless ‘single points of failure’), and struggled to support specialized work.
But eventually, new technologies and understandings gave factories both the reason and ability to be redesigned end-to-end for electricity, from replacing cogs with electric wires, to installing individual stations with bespoke and dedicated electrically-powered motors for functions such as sewing, cutting, pressing, and welding.
The benefits were wide-ranging. The same plant now had considerably more space, more light, better air, and less life-threatening equipment. What’s more, individual stations could be powered individually (which increased safety, while reducing costs and downtime), and use more specialized equipment (e.g. electric socket wrenches).
In addition, factories could configure their production areas around the logic of the production process, rather than hulking equipment, and even reconfigure these areas on a regular basis. These two changes meant that far more industries could deploy assembly lines in their plants (which had actually first emerged in the late 1700s), while those that already had such lines could extend them further and more efficiently. In 1913, for example, Henry Ford created the first moving assembly line, which used electricity and conveyor belts to reduce the production time per car from 12.5 hours to 93 minutes, while also using less power. According to historian David Nye, Ford’s famous Highland Park plant was “built on the assumption that electrical light and power should be available everywhere.”
Once a few plants began this transformation, the entire market was forced to catch up, thereby spurring more investment and innovation in electricity-based infrastructure, equipment, and processes. Within a year of its first moving assembly line, Ford was producing more cars than the rest of the industry combined. By its 10 millionth car, it had built more than half of all cars on the road.
This ‘second wave’ of industrial electricity adoption didn’t depend on a single visionary making an evolutionary leap from Thomas Edison’s core work. Nor was it driven just by an increasing number of industrial power stations. Instead, it reflected a critical mass of interconnected innovations, spanning power management, manufacturing hardware, production theory, and more. Some of these innovations fit in the palm of a plant manager’s hand, others needed a room, a few required a city, and they all depended on people and processes.
To return to Nye, “Henry Ford didn’t first conceive of the assembly line and then delegate its development to his managers. … [The] Highland Park facility brought together managers and engineers who collectively knew most of the manufacturing processes used in the United States … they pooled their ideas and drew on their varied work experiences to create a new method of production.” This process, which happened at national scale, led to the ‘roaring twenties’, which saw the greatest average annual increases in labor and capital productivity in a hundred years.
Powering the Mobile Internet
This is how to think about the mobile internet era. The iPhone feels like the start of the mobile internet because it united and/or distilled all of the things we now think of as ‘the mobile internet’ into a single minimum viable product that we could touch and hold and love. But the mobile internet was created — and driven — by so much more.
In fact, we probably don’t even mean the first iPhone but the second, the iPhone 3G (which saw the largest model-over-model growth of any iPhone, with over 4× the sales). This second iPhone was the first to include 3G, which made the mobile web usable, and operated the iOS App Store, which made wireless networks and smartphones useful.
But neither 3G nor the App Store were Apple-only innovations or creations. The iPhone accessed 3G networks via chips made by Infineon that connected via standards set by the ITU and GSMA, and which were deployed by wireless providers such as AT&T on top of wireless towers built by tower companies such as Crown Castle and American Tower. The iPhone had “an app for that” because millions of developers built them, just as thousands of different companies built specialized electric motor devices for factories in the 1920s. In addition, these apps were built on a wide variety of standards — from KDE to Java, HTML and Unity — which were established and/or maintained by outside parties (some of whom competed with Apple in key areas). The App Store’s payments worked because of digital payments systems and rails established by the major banks. The iPhone also depended on countless other technologies, from a Samsung CPU (licensed in turn from ARM), to an accelerometer from STMicroelectronics, Gorilla Glass from Corning, and other components from companies like Broadcom, Wolfson, and National Semiconductor.
All of the above creations and contributions, collectively, enabled the iPhone and started the mobile internet era. They also defined its improvement path.
Consider the iPhone 12, which was released in 2020. There was no amount of money Apple could have spent to release the iPhone 12 as its second model in 2008. Even if Apple could have devised a 5G network chip back then, there would have been no 5G networks for it to use, nor 5G wireless standards through which to communicate to these networks, and no apps that took advantage of its low latency or bandwidth. And even if Apple had made its own ARM-like GPU back in 2008 (more than a decade before ARM itself), game developers (which generate more than two thirds of App Store revenues) would have lacked the game-engine technologies required to take advantage of its superpowered capabilities.
Getting to the iPhone 12 required ecosystem-wide innovation and investments, most of which sat outside Apple’s purview (even though Apple’s lucrative iOS platform was the core driver of these advancements). The business case for Verizon’s 4G networks and American Tower Corporation’s wireless tower buildouts depended on the consumer and business demand for faster and better wireless for apps such as Spotify, Netflix and Snapchat. Without them, 4G’s ‘killer app’ would have been… slightly faster email. Better GPUs, meanwhile, were utilized by better games, and better cameras were made relevant by photo-sharing services such as Instagram. And this better hardware powered greater engagement, which drove greater growth and profits for these companies, thereby driving better products, apps, and services. Accordingly, we should think of the overall market as driving itself, just as the adoption of electrical grids led to innovation in small electric-powered industrial motors that in turn drove demand for the grid itself.
We must also consider the role of changing user capability. The first iPhone could have skipped the home button altogether, rather than waiting until the tenth. This would have opened up more room inside the device itself for higher-quality hardware or bigger batteries. But the home button was an important training exercise for what was a vastly more complex and capable mobile phone than consumers were used to. Like closing a clamshell phone, it was a safe, easy, and tactile way to ‘restart’ the iPhone if a user was confused or tapped the wrong app. It took a decade for consumers to be able to have no dedicated home button. This idea is critical. As time passes, consumers become increasingly familiar with advanced technology, and therefore better able to adopt further advances - some of which might have long been possible!
And just as consumers shift to new mindsets, so too does industry. Over the past 20 years, nearly every industry has hired, restructured, and re-oriented itself around mobile workflows, products, or business lines. This transformation is as significant as any hardware or software innovation — and, in turn, creates the business case for subsequent innovations.
Defining the Metaverse
This essay is the foreword to my nine-part and 33,000-word primer on the Metaverse, a term I’ve not yet mentioned, let alone described.
Before doing so, it was important for me to provide the context and evolutionary path of technologies such as ‘electricity’ and the ‘mobile internet’. Hopefully it provided a few lessons. First, the proliferation of these technologies fundamentally changed human culture, from where we lived to how we worked, what we made, what we bought, how, and from who. Second, these ‘revolutions’ or ‘transformations’ really depended on a bundle of many different, secondary innovations and inventions that built upon and drove one another. Third, even the most detailed understanding of these newly-emergent technologies didn’t make clear which specific, secondary innovations and inventions they required in order to achieve mass adoption and change the world. And how they would change the world was almost entirely unknowable.
In other words, we should not expect a single, all-illuminating definition of the ‘Metaverse’. Especially not at a time in which the Metaverse has only just begun to emerge. Technologically driven transformation is too organic and unpredictable of a process. Furthermore, it’s this very messiness that enables and results in such large-scale disruption.
My goal therefore is to explain what makes the Metaverse so significant – i.e. deserving of the comparisons I offered above – and offer ways to understand how it might work and develop.
The Metaverse is best understood as ‘a quasi-successor state to the mobile internet’. This is because the Metaverse will not fundamentally replace the internet, but instead build upon and iteratively transform it. The best analogy here is the mobile internet, a ‘quasi-successor state’ to the internet established from the 1960s through the 1990s. Even though the mobile internet did not change the underlying architecture of the internet – and in fact, the vast majority of internet traffic today, including data sent to mobile devices, is still transmitted through and managed by fixed infrastructure – we still recognize it as iteratively different. This is because the mobile internet has led to changes in how we access the internet, where, when and why, as well as the devices we use, the companies we patron, the products and services we buy, the technologies we use, our culture, our business model, and our politics.
The Metaverse will be similarly transformative as it too advances and alters the role of computers and the internet in our lives.
The fixed-line internet of the 1990s and early 2000s inspired many of us to purchase our own personal computer. However, this device was largely isolated to our office, living room or bedroom. As a result, we had only occasional access to and usage of computing resources and an internet connection. The mobile internet led most humans globally to purchase their own personal computer and internet service, which meant almost everyone had continuous access to both compute and connectivity.
Metaverse iterates further by placing everyone inside an ‘embodied’, or ‘virtual’ or ‘3D’ version of the internet and on a nearly unending basis. In other words, we will constantly be ‘within’ the internet, rather than have access to it, and within the billions of interconnected computers around us, rather than occasionally reach for them, and alongside all other users and real-time.
The progression listed above is a helpful way to understand what the Metaverse changes. But it doesn’t explain what it is or what it’s like to experience. To that end, I’ll offer my best swing at a definition:
“The Metaverse is a massively scaled and interoperable network of real-time rendered 3D virtual worlds which can be experienced synchronously and persistently by an effectively unlimited number of users with an individual sense of presence, and with continuity of data, such as identity, history, entitlements, objects, communications, and payments.”
Most commonly, the Metaverse is mis-described as virtual reality. In truth, virtual reality is merely a way to experience the Metaverse. To say VR is the Metaverse is like saying the mobile internet is an app. Note, too, that hundreds of millions are already participating in virtual worlds on a daily basis (and spending tens of billions of hours a month inside them) without VR/AR/MR/XR devices. As a corollary to the above, VR headsets aren’t the Metaverse any more than smartphones are the mobile internet.
Sometimes the Metaverse is described as a user-generated virtual world or virtual world platform. This is like saying the internet is Facebook or Geocities. Facebook is a UGC-focused social network on the internet, while Geocities made it easy to create webpages that lived on the internet. UGC experiences are just one of many experiences on the internet.
Furthermore, the Metaverse doesn’t mean a video game. Video games are purpose-specific (even when the purpose is broad, like ‘fun’), unintegrated (i.e. Call of Duty is isolated from fellow portfolio title Overwatch), temporary (i.e. each game world ‘resets’ after a match) and capped in participants (e.g. 1MM concurrent Fortnite users are in over 100,000 separated simulations. Yes, we will play games in the Metaverse, and those games may have user caps and resets, but those are games in the Metaverse, not the Metaverse itself. Overall, The Metaverse will significantly broaden the number of virtual experiences used in everyday life (i.e. well beyond video games, which have existed for decades) and in turn, expand the number of people who participate in them.
Lastly, the Metaverse isn’t tools like Unreal or Unity or WebXR or WebGPU. This is like saying the internet is TCP/IP, HTTP, or web browser. These are protocols upon which the internet depends, and the software used to render it.
The Metaverse, like the internet, mobile internet, and process of electrification, is a network of interconnected experiences and applications, devices and products, tools and infrastructure. This is why we don’t even say that horizontally and vertically integrated giants such as Facebook, Google or Apple are an internet. Instead, they are destinations and ecosystems on or in the internet, or which provide access to and services for the internet. And of course, nearly all of the internet would exist without them.
The Metaverse Emerges
As I’ve written before, the full vision of the Metaverse is decades away. It requires extraordinary technical advancements (we are far from being able to produce shared, persistent simulations that millions of users synchronized in real-time), and perhaps regulatory involvement too. In addition, it will require overhauls in business policies, and changes to consumer behavior.
But the term has become so recently popular because we can feel it beginning. This is one of the reasons why Fortnite and Roblox are so commonly conflated with the Metaverse. Just as the iPhone feels like the mobile internet because the device embodied the many innovations which enabled the mobile internet to go mainstream, these ‘games’ bring together many different technologies and trends to produce an experience which is simultaneously tangible and feels different from everything that came before. But they do not constitute the Metaverse.
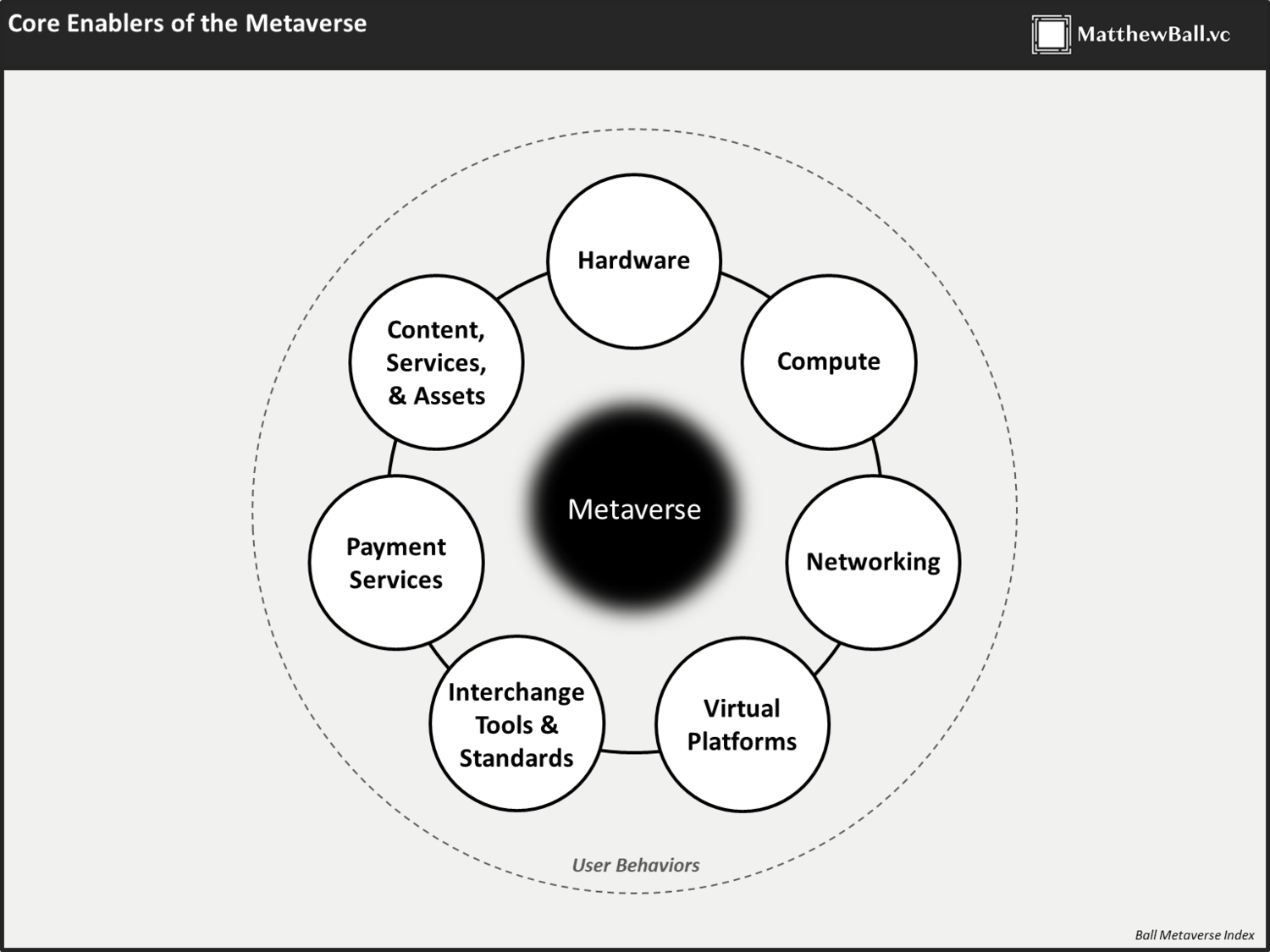
Personally, I’m tracking the emergence of the Metaverse around eight core categories, which can be thought of as a stack (click each header for a dedicated essay).
Hardware: The sale and support of physical technologies and devices used to access, interact with, or develop the Metaverse. This includes, but is not limited to, consumer-facing hardware (such as VR headsets, mobile phones, and haptic gloves) as well as enterprise hardware (such as those used to operate or create virtual or AR-based environments, e.g. industrial cameras, projection and tracking systems, and scanning sensors). This category does not include compute-specific hardware, such as GPU chips and servers, as well as networking-specific hardware, such as fiber optic cabling or wireless chipsets.
Networking: The provisioning of persistent, real-time connections, high bandwidth, and decentralized data transmission by backbone providers, the networks, exchange centers, and services that route amongst them, as well as those managing ‘last mile’ data to consumers.
Compute: The enablement and supply of computing power to support the Metaverse, supporting such diverse and demanding functions as physics calculation, rendering, data reconciliation and synchronization, artificial intelligence, projection, motion capture and translation.
Virtual Platforms: The development and operation of immersive digital and often three-dimensional simulations, environments, and worlds wherein users and businesses can explore, create, socialize, and participate in a wide variety of experiences (e.g. race a car, paint a painting, attend a class, listen to music), and engage in economic activity. These businesses are differentiated from traditional online experiences and multiplayer video games by the existence of a large ecosystem of developers and content creators which generate the majority of content on and/or collect the majority of revenues built on top of the underlying platform.
Interchange Tools and Standards: The tools, protocols, formats, services, and engines which serve as actual or de facto standards for interoperability, and enable the creation, operation and ongoing improvements to the Metaverse. These standards support activities such as rendering, physics, and AI, as well as asset formats and their import/export from experience to experience, forward compatibility management and updating, tooling, and authoring activities, and information management.
Payments: The support of digital payment processes, platforms, and operations, which includes fiat on-ramps (a form of digital currency exchange) to pure-play digital currencies and financial services, including cryptocurrencies, such as bitcoin and ether, and other blockchain technologies.
Metaverse Content, Services, and Assets: The design/creation, sale, re-sale, storage, secure protection and financial management of digital assets, such as virtual goods and currencies, as connected to user data and identity. This contains all business and services “built on top of” and/or which “service” the Metaverse, and which are not vertically integrated into a virtual platform by the platform owner, including content which is built specifically for the Metaverse, independent of virtual platforms.
User Behaviors: Observable changes in consumer and business behaviors (including spend and investment, time and attention, decision-making and capability) which are either directly associated with the Metaverse, or otherwise enable it or reflect its principles and philosophy. These behaviors almost always seem like ‘trends’ (or, more pejoratively, ‘fads’) when they initially appear, but later show enduring global social significance.
(You’ll note ‘crypto’ or ‘blockchain technologies’ are not a category. Rather, they span and/or drive several categories, most notably compute, interchange tools and standards, and payments — potentially others as well.)
Each of these buckets is critical to the development of the Metaverse. In many cases, we have a good sense of how each one needs to develop, or at least where there’s a critical threshold (say, VR resolution and frame rates, or network latency).
But ultimately, how these many pieces come together and what they produce is the hard, important, and society-altering part of any Metaverse analysis. Just as the electricity revolution was about more than the kilowatt hours produced per square mile in 1900s New York, and the internet about more than HTTP and broadband cabling.
Based on precedent, however, we can guess that the Metaverse will revolutionize nearly every industry and function. From healthcare to payments, consumer products, entertainment, hourly labor, and even sex work. In addition, altogether new industries, marketplaces and resources will be created to enable this future, as will novel types of skills, professions, and certifications. The collective value of these changes will be in the trillions.
Is the time crystal really an otherworldly revolution, leveraging quantum computing that will change physics forever?
KEY TAKEAWAYS
Google’s quantum computing team, in a first, has developed and demonstrated a discrete time crystal on a quantum computer.
By driving the system with a microwave pulse, they can get it to return to its original quantum state periodically, with no thermal noise or decoherence effects.
However, claims that it violates thermodynamics, is otherworldly, or changes physics forever are all demonstrably untrue and misrepresentative of the actual quality research.
It is tempting, whenever a new discovery comes along, to imagine a whole slew of revolutions that might soon ensue. After all, anytime you can suddenly do or accomplish any task that was previously impractical or even (thought to be) impossible, that is one less obstacle standing in the way of even your loftiest, pie-in-the-sky dreams. However, no matter what discoveries ensue, the fundamental laws of physics that underlie reality must always be obeyed; you might be able to cajole nature into doing a lot of clever things, but you cannot very well break the rules that govern it. If you could, we would have to write down new laws, because the old ones would no longer be valid. Despite all the tricks we have developed, we cannot create fundamental magnetic monopoles, violate the conservation of momentum or energy, or work our way around the second law of thermodynamics.
Yet a recent article, touting a brand new discovery involving time crystals and Google’s quantum computer, claims to do just that: evade the second law of thermodynamics. Is that even right? Patreon supporter Chad Marler wants to know, asking:
Hi Ethan… I was reading some headlines and came across this article. While I suspect the innovation was real, some of the wording in the article made my [nonsense] detector go off… it sounds like something you would hear on an Art Bell show.
I will tell you, up front, that the scientific paper is legit, but the recent article is full of misconceptions and misinterpretations. Let’s dive in and find out what it is all about.
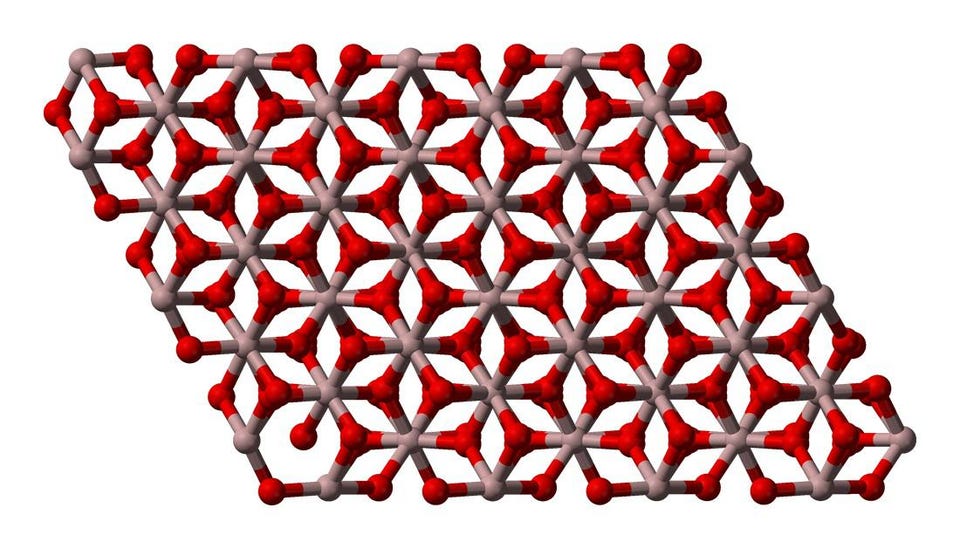
Normal crystals repeat their structure/configuration in space, like the crystal structure of corundum, α-Al2O3. But a time crystal would repeat its quantum state in time, instead. (Credit: Ben Mills)
What is a time crystal?
Unlike most things in physics, where theorists imagine a possibility far out of reach of current or near-future technology, time crystals have only been around for a very short time, even in our minds. In 2012, Nobel Laureate Frank Wilczek proposed that a new state of matter might exist: a time crystal. Most of us know what a normal crystal is: a repeating, rigid lattice or grid of particles, like atoms or molecules, that compose a solid, ordered structure.
When we talk about time crystals, however, there is no lattice, no grid, and no solid, ordered structure. The important component of a time crystal, at least conceptually, is the “repeating” part. Whereas a conventional crystal has a structure that repeats in space, meaning it exhibits translational symmetry (if you move within the crystal, the structure looks the same everywhere), a time crystal should repeat its configuration, periodically, in time.
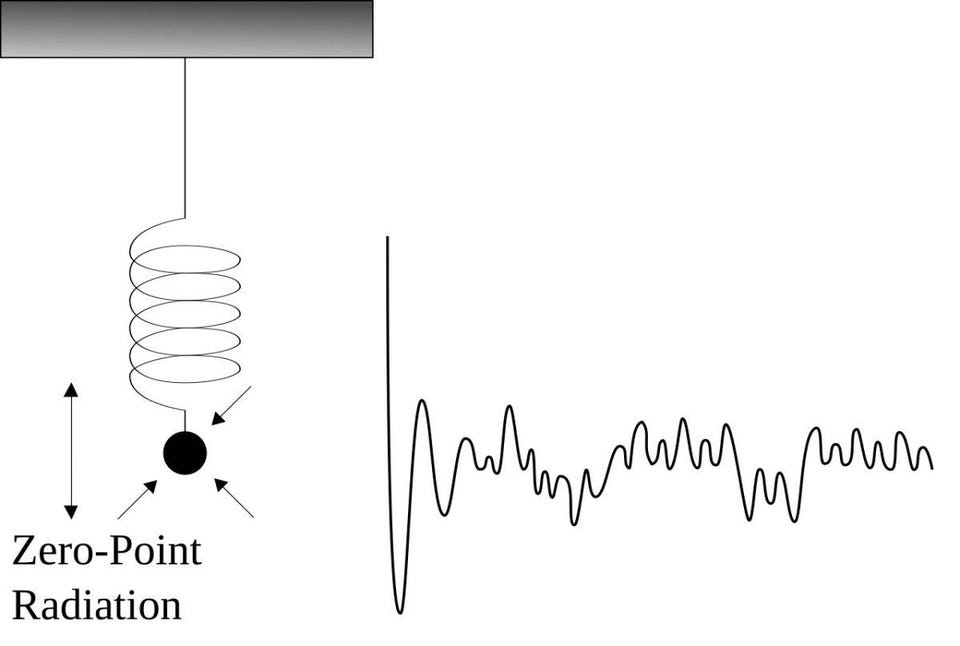
Even in their ground state, electrons still have a non-zero energy, meaning that there will always be random motions over time. Only if the system returns to the exact original state, periodically, with no thermal noise or other imperfections, can a time crystal be created. (Credit: SPARKYSCIENCE AND ANTICOMPOSITENUMBER)
Originally, when time crystals were first considered, they were presumed to be impossible for a number of reasons. There were theorems published that proved their impossibility. There were assertions that a system that transitioned from lower-to-higher energy states would not return to its original state again spontaneously, and then go back-and-forth between those two states, because that would indicate some type of perpetual motion, violating the second law of thermodynamics and the conservation of energy.
But not only did theorists find loopholes in those theorems, but more impressively, experimentalists just went right ahead and created them in the lab. In 2016, Norman Yao and his team came up with a scheme to create a time crystal through a very clever plan. Instead of taking a closed, constant system, he proposed leveraging a system with out-of-equilibrium conditions. He would then “drive” that system externally, making it an open (rather than a closed) system and achieving the much sought after “time crystal” state.
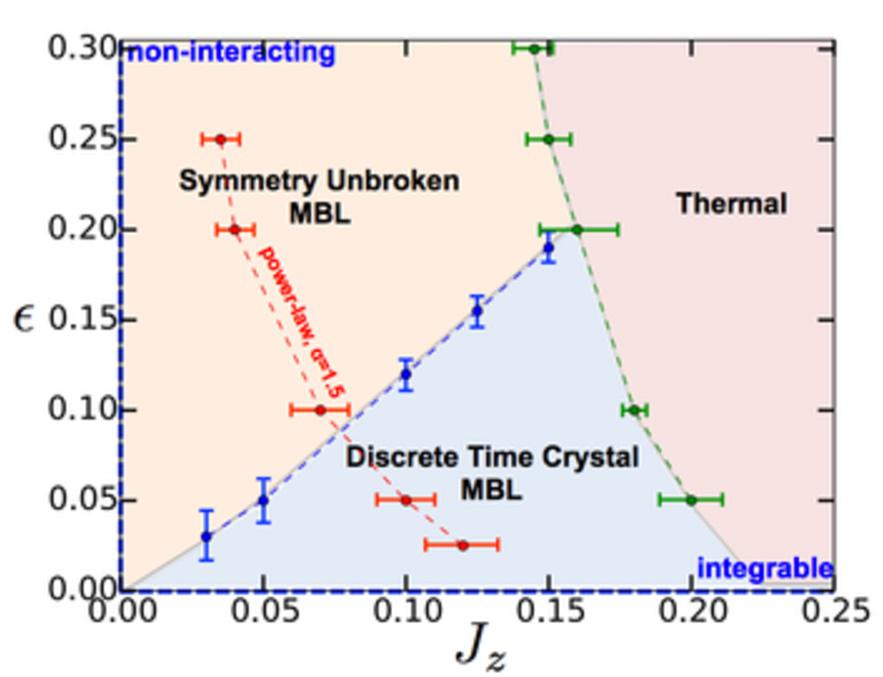
Phase diagram of the discrete time crystal as a function of Ising interaction strength and spin-echo pulse imperfections. Only in the blue, shaded region is the time crystal state achieved, where the X-axis is the dipole spins (interaction strength) and the Y-axis is the driving force (pulses) injected into the system. (Credit: Norman Y. Yao, Andrew C. Potter, Ionut-Dragos Potirniche, Ashvin Vishwanath.)
It is a little bit complicated, but you can imagine that you have a bunch of atoms that have a spin, and those spins have directions: dipole moments. The way you can “drive” the system is by subjecting the system to spin-echo pulses that contain imperfections, but which occur periodically while allowing interactions to randomly occur in the intermediate times. If you get the combinations of these dipole moments of the spins and the spin-echo pulses to behave in a certain fashion, you could get a time crystal.
The hard part, though, is avoiding what normally happens when you interact with a system: If there is an exchange of energy, that energy gets transferred throughout the system, internally, causing runaway heating due to many-body interactions. Somehow, you have to:
drive the system, externally, with a spin-flip pulse,
so that you get a periodic response,
that is proportional to the time at which you pulse the system,
and at some multiple of the period, you return to your initial state,
while the “time crystal” only oscillates away from and then back into that initial state.
Only if you go back, periodically, to exactly your initial state, with no extra heating and achieve a pure steady-state can you make a time crystal.
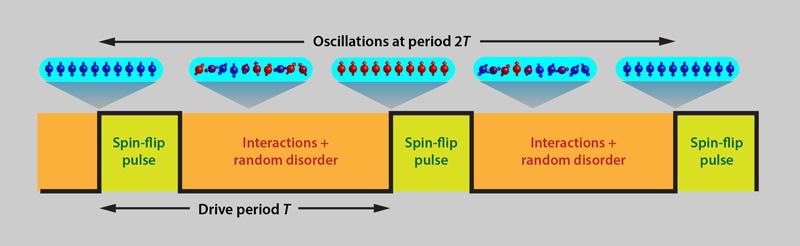
The blueprint for creating a time crystal: take an entangled system and drive it with a spin-flip pulse. At some multiple of the period, you will return to the same initial state. (Credit: APS / Alan Stonebraker / Phil Richerme)
They tried to set up a system precisely as Yao had demanded but, because the conditions are so general, wound up taking vastly different approaches.
Monroe’s group took a series of yttrium atoms all lined up, in a one-dimensional line, all coupled together via their electrostatic interactions. When they subjected this atomic line to a series of spin-flip pulses, they found that the system would return to its initial state every two full pulse periods. Meanwhile, Lukin’s group took an actual diamond crystal that contained somewhere on the order of ~1,000,000 spin-impurities within it and pulsed those impurities within the crystal with microwave radiation. That radiation flipped their spins, but time crystal oscillations were only observed every three full pulse periods — whereupon the crystal would return to its initial quantum state.
The Harvard Diamond, created by a team led by Mikhail Lukin, has so many nitrogen impurities that it turned black. This is one of two independent physical systems used to create a time crystal. When driven under the proper conditions, it returns to its initial state, whatever that state may have been, every three full pulse periods. (Credit: Georg Kucsko.)
This occurred for both groups, interestingly enough, even when the driving pulses were imperfect. You could:
alter the magnitude of the pulse, making it stronger or weaker,
vary the frequency of pulsation, making it a little quicker or slower,
turn up or turn down the amount of noise and/or interactions that occurred between the pulses,
or change the conditions of the environment that the system is placed in,
and still recover this time crystal behavior. Surprisingly, for these non-equilibrium systems, there is a lot of wiggle-room as far as what you can do and still observe this time crystal behavior.
But as they were originally envisioned by Wilczek in 2012, an idealized time crystal would occur in a system that was in thermal equilibrium — that was neither absorbing nor emitting energy from or to the surrounding environment. In order to create a time crystal, you needed to have an open system that could exchange energy with its external surroundings, and that system needed to be driven at a periodic frequency. Moreover, the imperfections in the driving could not be too large, or the crystal would “melt” in precisely the fashion we want to avoid: with runaway heating occurring from many-body interactions.
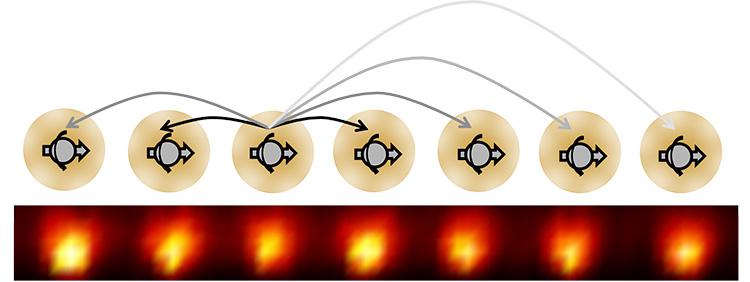
Ten yttrium atoms with entangled electron spins, as used to first create a time crystal. With every two full pulse periods that pass, the full suite of atoms returns to its original, initial configuration of spins. (Credit: Chris Monroe, University of Maryland.)
What did the Google team, using a quantum computer, actually do?
Back when these time crystals were first realized in 2016/2017, it was recognized that time crystals could conceivably be applied to quantum computers. Instead of encoding a bit, like the “0” or “1” a standard computer encodes, a quantum computer encodes a qubit, which is a probability-weighted superposition of both “0” and “1” simultaneously. Although you can only measure a “0” or “1” at the end, the fact that you have many qubits allows you to see whether you have preserved the quantum behavior of the system (or not), whether your results are error-free (or not), and what type of final-state distribution you get and whether it matches your theoretical predictions.
The hard “problem” with a quantum computer is the problem of decoherence: Over relatively short timescales, the system interacts with the surrounding particles, and this causes you to lose the quantum behavior you are trying to preserve. For Google’s quantum computer, which is based on superconducting qubits (as opposed to quantum dots or ion traps, for example), you get a coherence timescale of about 50 microseconds. You can only perform perhaps a few dozen computations before decoherence ruins your experiment, and you lose the quantum behavior you sought to maintain and measure. (Or, more precisely, before too many errors, including errors from simple crosstalk between qubits, simply transform your signal into noise.)
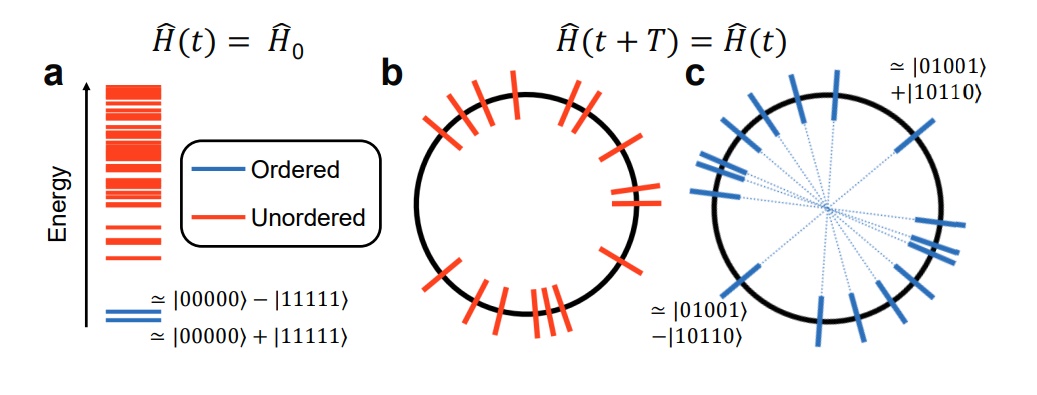
The ordered and disordered eigenstates of a set of configurations. In equilibrium (a), only the lowest energy states are ordered, with higher-energy ones being unordered. In most driven systems (b), no states are ordered. But in systems with many-body localization (c), all states can be ordered, allowing for the possibility of returning periodically to your original state. (Credit: Google Quantum AI and collaborators, arXiv:2107.13571.)
Instead of using a dynamical phase like the spins of atoms, though, a quantum computer allows you to use a different property: the order of eigenstates in many-body systems. If you brought your qubits into an equilibrium setting, you would see that there was order in the lowest energy states and unordered states at higher energies. That is why, under normal circumstances, if you allow too much energy to propagate through your system, you just wind up with featureless, unordered systems; it is like the heat or energy just randomized everything.
However, some systems can exhibit what is called MBL: many-body localization, where you get local conservation laws and only a discrete number of ordered states. When you drive the system, which the Google team did with pulsed microwaves that cause the qubits to flip, your qubits have the potential to behave just like the dynamical phases did when we were measuring atomic spins: If the qubits do not absorb heat or impart energy to their surroundings, they can simply flip between different ordered states. With enough pulses, you can conceivably recover your original state.
Sure enough, every two full periods of the microwave pulses resulted in a recovery of the original state: a time crystal. Not bound by these decoherence effects any longer, the researchers could maintain this time crystal state for up to ~100 seconds, a remarkable achievement.
The Sycamore processor, which is a rectangular array of 54 qubits connected to its four nearest neighbros with couplers, contains one inoperable qubit, leading to an effective 53 qubit quantum computer. The optical image shown here illustrates the scale and color of the Sycamore chip as seen in optical light. (Credit: Google Quantum AI and collaborators, retrieved from NASA.)
Although the article does a fine job of describing the experiments performed themselves, there is a howler of a statement made early on:
With the ability to forever cycle between two states without ever losing energy, time crystals dodge one of the most important laws of physics — the second law of thermodynamics, which states that the disorder, or entropy, of an isolated system must always increase. These bizarre time crystals remain stable, resisting any dissolution into randomness, despite existing in a constant state of flux.
There is no dodge; the second law of thermodynamics applies to closed systems, not open ones. The disorder of the system, if you include the microwave pulses and the external environment, does in fact go up, just as predicted. The crystals oscillate between allowable states and return to their original ones when driven properly, just as their non-qubit analogues did years prior. In order to do this, the researchers needed to discriminate between external decoherence and internal thermalization, both of which can destroy the quantum state they are seeking to maintain, which itself is an admirable achievement.
When a series of food items are placed in a pan and the chef jiggles it in a way to coax the items into flipping, some will flip 180°, others 360°, others 540°, etc. But if the chef jiggles it enough times, all the items may return to their original state, rather than taking on random configurations. This is the concept of a time crystal. (Credit: Public domain / Creative Commons CC0.)
Although it may be fun to claim, as the headline of the article did, that this is “otherworldly” and “could change physics forever,” it is more like imagining you have got a skillet with different sized and shaped mollusks in it and a chef who jiggles the pan in a way that makes the shelled creatures flip. Some will flip 180°, others 360°, others 540°, etc. In the quantum world, some of these mollusks can take on in-between values, too. But after a certain number of jiggles, the mollusks all wind up the same way they started, regardless of what that specific initial configuration was. That is all the Google team is doing, but instead of mollusks or spinning atoms, they are using the eigenstates of a quantum computer.
Which, if we are being honest, is still a remarkable achievement! This is a new kind of time crystal, a new way of achieving it, and one with the potential to study non-equilibrium phases of matter on a quantum computer. And although you have to pump energy into the system in pulses, the time crystal can, in fact, return to whatever specific state it began with, even with small imperfections occurring in the “flips,” without destroying, decohering, or losing the nature of the quantum state due to thermal instabilities. No laws are violated and the physics we know is not changed in any way, but this is a phenomenal achievement nonetheless. In a mere nine years, we have gone from theorizing the existence of time crystals to creating them to observing them on a quantum processor. When a new field yields significant advances so quickly, it compels us to pay attention.
Blockchain is a distributed ledger technology that is revolutionizing the way we conduct transactions, protect our identity, and preserve our privacy. By providing a secure and transparent platform for recording and verifying transactions, blockchain is fortifying the traditional finance system and unlocking new opportunities for innovation and growth. With its decentralized and immutable nature, blockchain is also empowering individuals to take control of their personal data and protect it from unauthorized access and exploitation. Whether you are a business owner, investor, or consumer, blockchain is a technology that you cannot afford to ignore in today's digital age.
Blockchain and AI are revolutionizing the way we perceive identity. With virtual identity tokenization, individuals can take ownership of their digital self and protect their data. The impact of this technology is inevitable, and it will change the way we interact with the digital world forever.
The anime classic Ghost in the Shell has been praised for its exploration of transhumanist themes, questioning what it means to be human in a world where artificial intelligence is advancing rapidly. The central question of the film is whether AI is just a shell, or if it is capable of developing true consciousness and emotions.
As our lives become more intertwined with technology, the concept of virtual identity has become increasingly important. From social media profiles to online banking accounts, our virtual identities can have a significant impact on our lives. However, with the rise of AI and other advanced technologies, questions about the ethics of virtual identity are becoming more complex. In this article, we will explore the different systems and technologies that make up virtual identity, as well as the ethical considerations that must be taken into account when developing these systems.
As technology continues to advance, our lives are becoming increasingly intertwined with virtual spaces. From social media platforms to online gaming communities, virtual identities have become an integral part of our daily lives. In these virtual spaces, we have the opportunity to express ourselves, interact with others, and explore new identities. However, as we spend more time in these virtual spaces, it is important that we understand the systems, behaviours, and ethics related to virtual identities.
Virtual Identity and Digital Integrity In today’s digital age, virtual identity has become an integral part of our online existence. It is the representation of who we are in the digital world, and it plays a significant role in our interactions with the online community. However, the growing concern of identity theft and data breaches
04 Feb’23 | By Amit Ghosh As the country pushes its sustainability agenda, the use of new technology deserves a closer look in order to make a difference in this cause When we examine blockchain’s role in environmental, social, and governance (ESG) policies and markets around the world, we can see how technology is already changing ESG













You must be logged in to post a comment.